Deep Learning: Natural Language Processing (Part 2)
Content
- Content
- High performance NLP
- ELMo: Embeddings from Language Models
- USE: Universal Sentence Encoder
- BERT: Bidirectional Encoder Representations from Transformers
- XLNet
High performance NLP
ELMo: Embeddings from Language Models
This model was published early in 2018 and uses Recurrent Neural Networks (RNNs) in the form of Long Short Term Memory (LSTM) architecture to generate contextualized word embeddings
ELMo, unlike BERT and the USE, is not built on the transformer architecture. It uses LSTMs to process sequential text. ELMo is like a bridge between the previous approaches such as GLoVe and Word2Vec and the transformer approaches such as BERT.
Word2Vec approaches generated static vector representations or words which did not take order into account. There was one embedding for each word regardless of how it changed depending on the context, e.g. the word right, as in it is a human right, take a right turn, and that is the right answer.
ELMo provided a significant step towards pre-training in the context of NLP. The ELMo LSTM would be trained on a massive dataset in the language of our dataset, and then we can use it as a component in other models that need to handle language.
What’s ELMo’s secret?
ELMo gained its language understanding from being trained to predict the next word in a sequence of words - a task called Language Modeling. This is convenient because we have vast amounts of text data that such a model can learn from without needing labels.
Archiecture
ELMo word vectors are computed on top of a two-layer bidirectional language model (biLM). This biLM model has two layers stacked together. Each layer has 2 passes — forward pass and backward pass:

Unlike traditional word embeddings such as word2vec and GLoVe, the ELMo vector assigned to a token or word is actually a function of the entire sentence containing that word. Therefore, the same word can have different word vectors under different contexts.
Reference:
USE: Universal Sentence Encoder
The Universal Sentence Encoder encodes text into high dimensional vectors that can be used for text classification, semantic similarity, clustering and other natural language tasks.
The model is trained and optimized for greater-than-word length text, such as sentences, phrases or short paragraphs. It is trained on a variety of data sources and a variety of tasks with the aim of dynamically accommodating a wide variety of natural language understanding tasks. The input is variable length English text and the output is a 512 dimensional vector. We apply this model to the STS benchmark for semantic similarity, and the results can be seen in the example notebook made available. The universal-sentence-encoder model is trained with a deep averaging network (DAN) encoder.
Architecture
Text will be tokenized by Penn Treebank(PTB) method and passing to either transformer architecture or deep averaging network. As both models are designed to be a general purpose, multi-task learning approach is adopted. The encoding model is designed to be as general purpose as possible. This is accomplishedby using multi-task learning whereby a single encoding model is used to feed multiple down-stream tasks. The supported tasks include:
- Same as Skip-though, predicting previous sentence and next sentence by giving current sentence.
- Conversational response suggestion for the inclusion of parsed conversational data.
- Classification task on supervised data

Transformer architecture is developed by Google in 2017. It leverages self attention with multi blocks to learn the context aware word representation.
Deep averaging network (DAN) is using average of embeddings (word and bi-gram) and feeding to feedforward neural network.
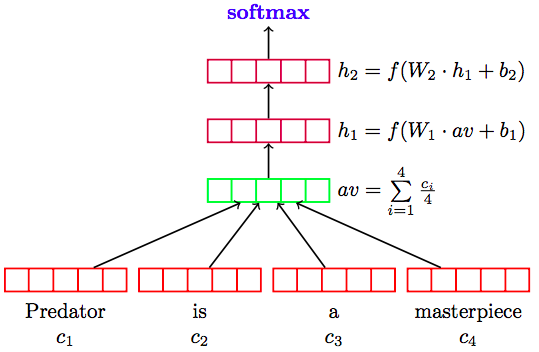
The reasons of introducing two models because different concern. Transformer architecture achieve a better performance but it needs more resource to train. Although DAN does not perform as good as transformer architecture. The advantage of DAN is simple model and requiring less training resource.
Why USE works better for sentence similarity task?
Reference:
BERT: Bidirectional Encoder Representations from Transformers
*In case the above link is broken, click here
Architecture
BERT is trained on two main tasks:
![]() Masked language model: Where some words are hidden (15% of words are masked) and the model is trained to predict the missing words
Masked language model: Where some words are hidden (15% of words are masked) and the model is trained to predict the missing words
![]() Next sentence prediction: Where the model is trained to identify whether sentence B follows (is related to) sentence A.
Next sentence prediction: Where the model is trained to identify whether sentence B follows (is related to) sentence A.
The new XLNet model improves on BERT since it uses the transformer XL, an extension of the transformer which enables it to deal with longer sentences than BERT.
Reference:
XLNet