Practical Deep Learning
Content
- Content
- Gradient Checkpointing
- Optimizing models using the PyTorch JIT
- PyTorch Tips
- Numpy Tips
- Sharded Training - train deep learning models on multiple GPUs
- Deep Learning Best Practices - Mistakes and Tips:
- Technical Mistakes while Model Building
- Software Engineering Skills for Data Science
- Manage Virutal Environment
- Pytorch Learning
- 9 Tips For Training Lightning-Fast Neural Networks In Pytorch
- How to write training loop in PyTorch?
-
How to use
checkpointin your code? -
Why you should use
torch.no_grad()instead ofmodel.eval()? - Learning rate finder PyTorch
- Dive into Deep Learning with PyTroch
- How to design and debug deep learning models?
- Understanding loss:
Gradient Checkpointing
It can lower the memory requirement of deep neural networks quite substantially, allowing us to work with larger architectures and memory limitations of conventional GPUs. However, there is no free lunch here: as a trade-off for the lower-memory requirements, additional computations are carried out which can prolong the training time. However, when GPU-memory is a limiting factor that we cannot even circumvent by lowering the batch sizes, then gradient checkpointing is a great and easy option for making things work!
Reference:
![]()
Optimizing models using the PyTorch JIT
Reference:
![]()
PyTorch Tips
Numpy Tips
- CS224U Numpy
-
NumPy Illustrated: The Visual Guide to NumPy

-
Numpy visual guide - jalammar
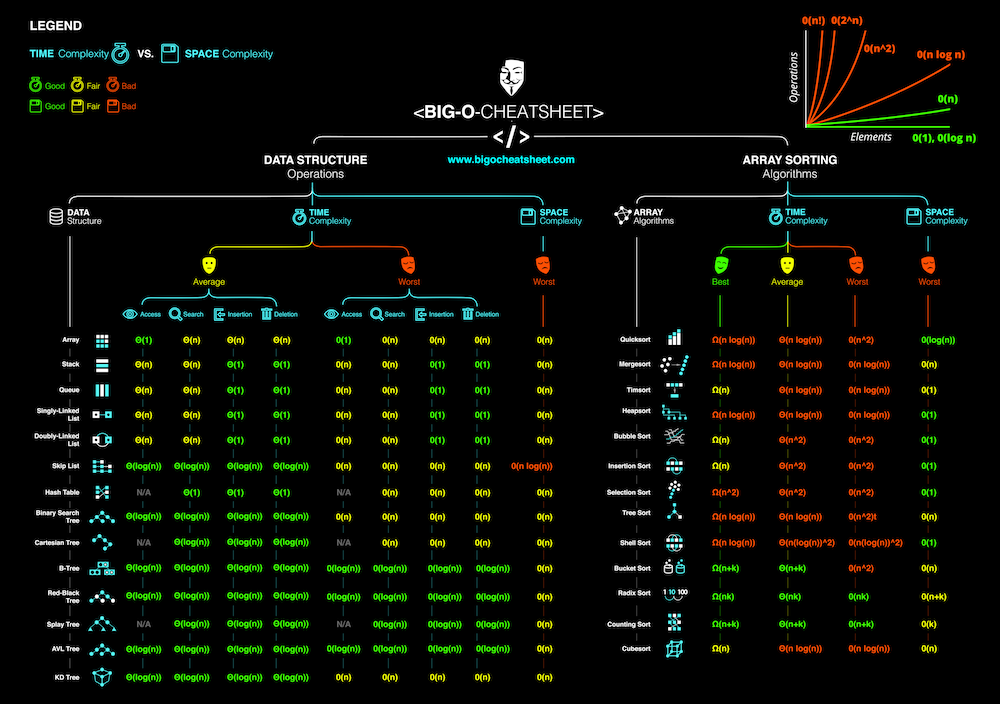
- Time complexity
- Big-O cheat sheet
![]()
Sharded Training - train deep learning models on multiple GPUs
Training large neural network models can be computationally expensive and memory hungry. There have been many advancements to reduce this computational expense, however most of them are inaccessible to researchers, require significant engineering effort or are tied to specific architectures requiring large amounts of compute.
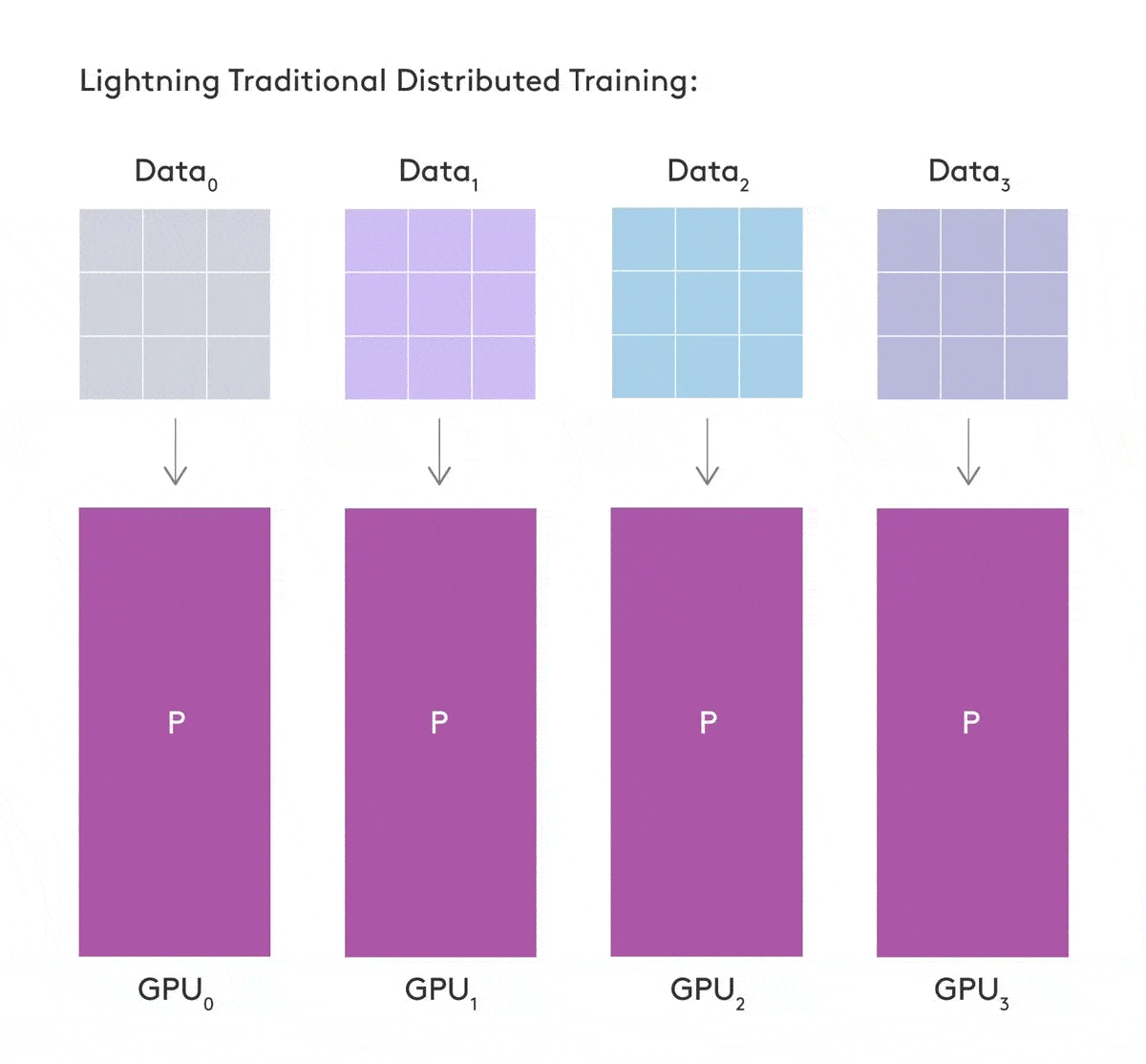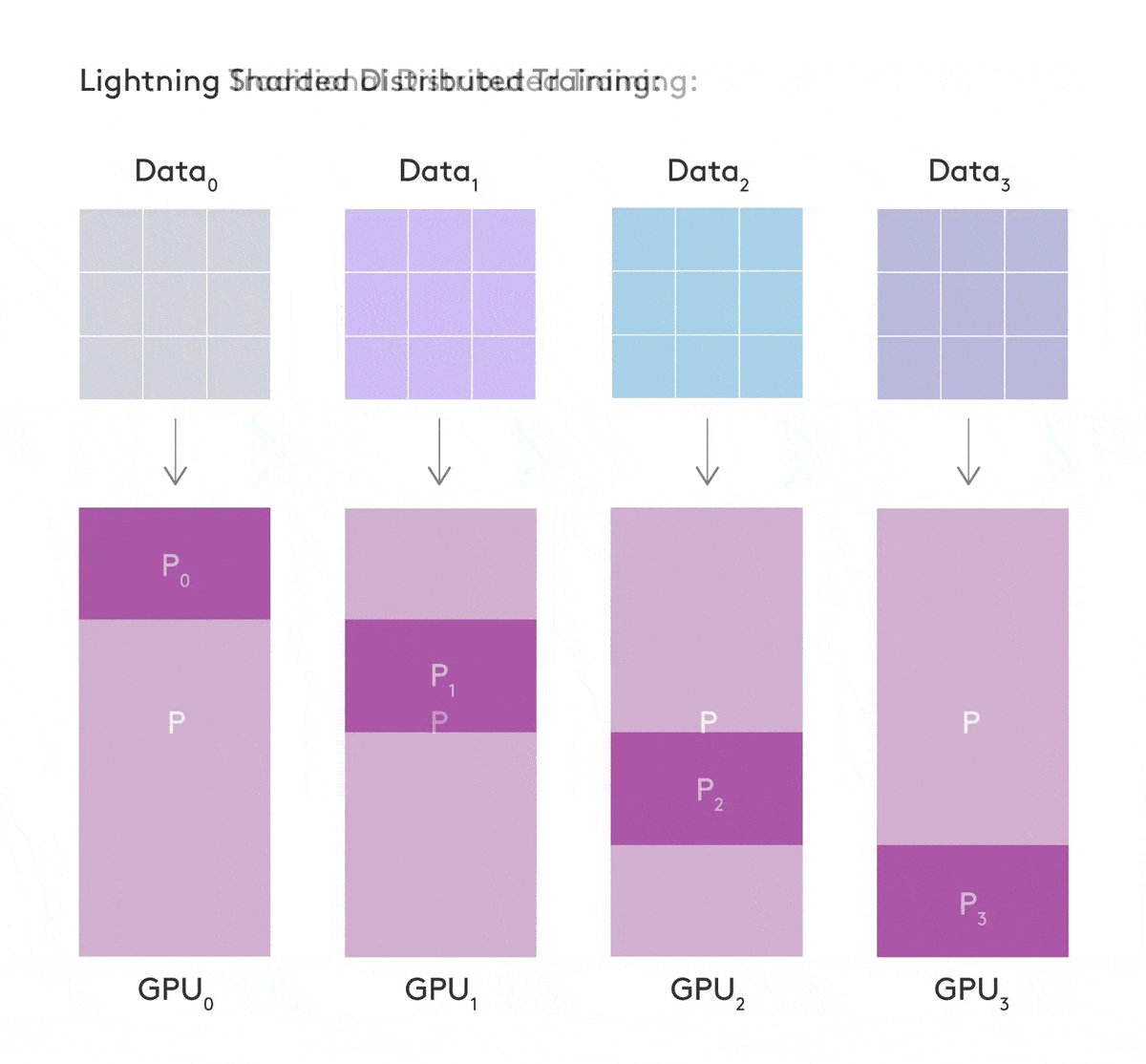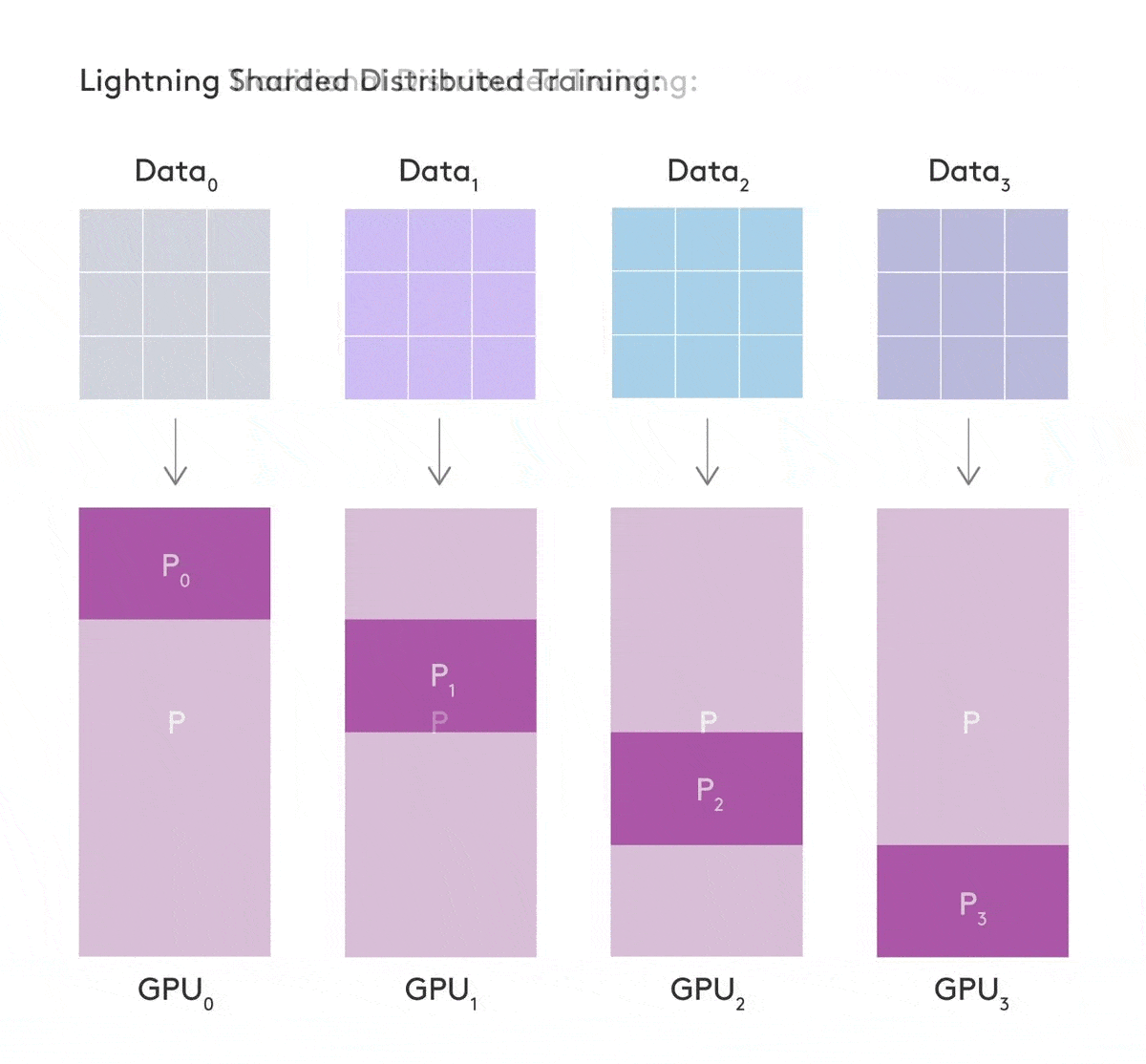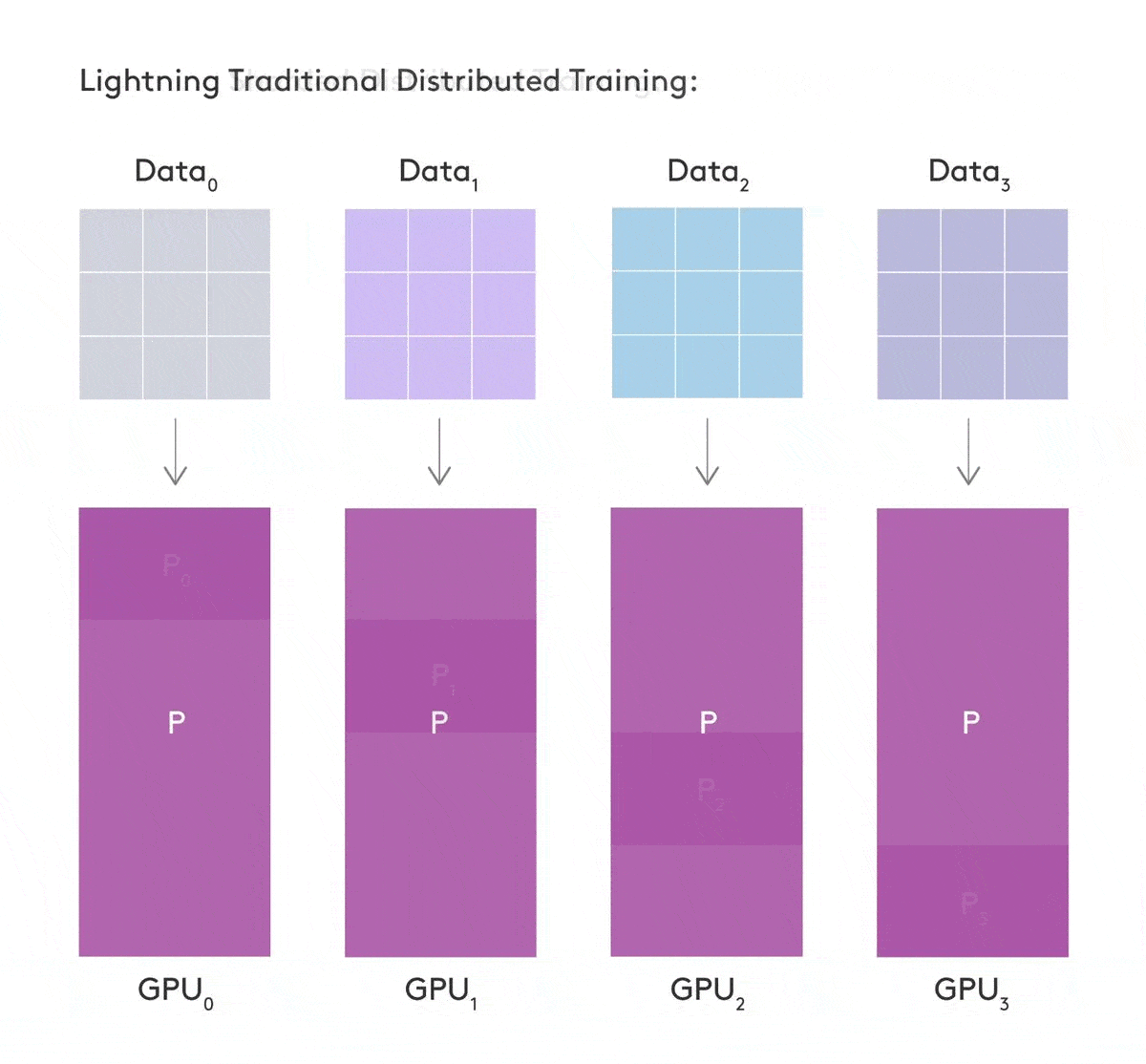
Reference:
![]()
Deep Learning Best Practices - Mistakes and Tips:
The purpose of this repo is to consolidate all the Best Practices for building neural network model curated over the internet
- Try to overfit a single batch first
- It’s a very quick sanity test of your wiring; i.e. if you can’t overfit a small amount of data you’ve got a simple bug somewhere
- it’s by far the most “bang for the buck” trick that noone uses that exists. 5 replies 7 retweets 219 likes
- Forgot to toggle train/eval mode for the net
- Forgot to
.zero_grad()(in pytorch) before.backward(). - Passed
softmaxed outputsto a loss that expectsraw logits. - You didn’t use
bias=Falsefor yourLinear/Conv2dlayer when usingBatchNorm, or conversely forget to include it for the output layer .This one won’t make you silently fail, but they are spurious parameters - Thinking
view()andpermute()are the same thing (& incorrectly using view) - starting with
small model+small amount of data& growing both together; I always find it really insightful- I like to start with the simplest possible sanity checks - e.g. also training on all zero data first to see what loss I get with the base output distribution, then gradually include more inputs and scale up the net, making sure I beat the previous thing each time.
- …
Reference
These are pure gold.
-
Tweet_andrej_karpathy
- Recipe for training neural network
- What should I do when my neural network doesn’t learn?
- Practical Advice for Building Deep Neural Networks
Technical Mistakes while Model Building
- Create a
non-reproducibledata preparation steps - Evaluate a model based on performance of training set
- Didn’t notice
large outlier - Dropped missing values when it made sense to flag them
- Flagged missing values when it made sense to drop them
- Set missing values to Zero
- Not comparing a complex model to a simple baseline
- Failed to understand nuances of data collection
- Build model for wrong point in time
- Deleted records with missing values
- Predicted the wrong outcome
- Made faulty assumptions about
time zones - Made faulty assumptions about
data format - Made faulty assumptions about
data source - Included
anachronistic(belonging to a period other than that being portrayed) variables - Treated categorical variables as continuous
- Treated continuous variables as categorical
- Filtered training set to incorrect population
- Forgot to include
y-variablein the training set - Didn’t look at number of missing values in column
- Not filtering for duplicates in the dataset
- Accidently included
IDfield as predictors - Failing to bin or account for rare categories
- Using proxies of outcomes as predictors
- Incorrect handling of
missing values - Capped outliers in a way that didn’t make sense with data
- Misunderstanding of variable relationships due to incomplete EDA
- Failed to create calculated variables from raw data
- Building model on the wrong population
Reference:
Software Engineering Skills for Data Science
Because our day-to-day involves writing code, I am convinced that we data scientists need to be equipped with basic software engineering skills. Being equipped with these skills will help us write code that is, in the long-run, easy to recap, remember, reference, review, and rewrite. In this collection of short essays, I will highlight the basic software skills that, if we master, will increase our efficiency and effectiveness in the long-run.
Reference:
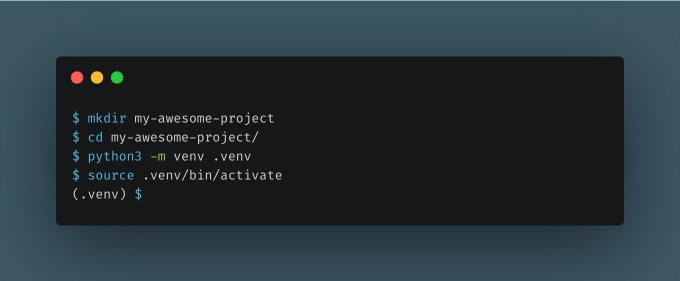
Manage Virutal Environment
Apart from conda, Using the built-in venv module in Python3 we can create a new virtual environment.
Pytorch Learning
9 Tips For Training Lightning-Fast Neural Networks In Pytorch
How to write training loop in PyTorch?
How to use checkpoint in your code?
What is checkpoint?
- The architecture of the model, allowing you to re-create the model
- The weights of the model
- The training configuration (loss, optimizer, epochs, and other meta-information)
- The state of the optimizer, allowing to resume training exactly where you left off.
Again, a checkpoint contains the information you need to save your current experiment state so that you can resume training from this point.
How to save and load checkpoint in Pytorch?
#Saving a checkpoint
torch.save(checkpoint, ‘checkpoint.pth’)#Loading a checkpoint
checkpoint = torch.load( ‘checkpoint.pth’)
A checkpoint is a python dictionary that typically includes the following:
- Network structure: input and output sizes and Hidden layers to be able to reconstruct the model at loading time.
-
Model state dict: includes parameters of the network layers that is learned during training, you get it by calling this method on your model instance.
model.state_dict() -
Optimizer state dict: In case you are saving the latest checkpoint to continue training later, you need to save the optimizer’s state as well.
you get it by calling this method on an optimizer’s instance
optimizer.state_dict() - Additional info: You may need to store additional info, like number of epochs and your class to index mapping in your checkpoint.
#Example for saving a checkpoint assuming the network class named #Classifier
checkpoint = {'model': Classifier(),
'state_dict': model.state_dict(),
'optimizer' : optimizer.state_dict()}
torch.save(checkpoint, 'checkpoint.pth')
def load_checkpoint(filepath):
checkpoint = torch.load(filepath)
model = checkpoint['model']
model.load_state_dict(checkpoint['state_dict'])
for parameter in model.parameters():
parameter.requires_grad = False
model.eval()
return model
model = load_checkpoint('checkpoint.pth')
Reference:
- saving-loading-your-model-in-pytorch
- checkpointing-tutorial-for-tensorflow-keras-and-pytorch
- Notebook-Github
Why you should use torch.no_grad() instead of model.eval()?
It’s more memory efficient and runs faster. It’s a very handy operation that can save you from CUDA Out of memory error.
Because many times, in the evaluation() step using the validation dataset and dataloader, you may face this CUDA OOM error.
# RuntimeError: cuda runtime error (2) : out of memory at /data/users/soumith/miniconda2/conda-bld/pytorch-0.1.9_1487346124464/work/torch/lib/THC/generic/THCStorage.cu:66
That time torch.no_grad() will help you. So it’s better to use this instead of model.eval()
Use of volatile in gpu memory improvement?
From the comment section of this github issue #958
Sample error
# RuntimeError: cuda runtime error (2) : out of memory at /data/users/soumith/miniconda2/conda-bld/pytorch-0.1.9_1487346124464/work/torch/lib/THC/generic/THCStorage.cu:66
Same error occurred to me in the same situation. It was solved by changing volatile in Variable() when inference i.e using val_data. If we set volatile=True, the computational graph will be retained during inference. But in inference time, we don’t need to retain computational graphs. It’s very memory consuming.
You can just set flags of volatile to True like this, Variable(x, volatile=True).
Read the comments of the issue page mentioned above.
See how to use volatile=True in inference time.
if phase == 'train':
scheduler.step()
........
for data in dataloaders[phase]: ## Iterate over data.
inputs, labels = data ## get the inputs
if use_gpu: ## pass them into GPU
inputs = inputs.cuda()
labels = labels.cuda()
if phase == 'train': ## wrap them in Variable
inputs, labels = Variable(inputs), Variable(labels)
else:
inputs = Variable(inputs, volatile=True)
labels = Variable(labels, volatile=True)
Learning rate finder PyTorch

Dive into Deep Learning with PyTroch
How to design and debug deep learning models?
[1/4] Learning ML engineering is a long slog even for legendary hackers like @gdb
IMO, the two hardest parts of ML eng are:
- Feedback loops are measured in minutes or days in ML (compared to seconds in normal eng)
- Errors are often silent in ML
[2/4] Most ML people deal with silent errors and slow feedback loops via the ratchet approach:
- Start with known working model
- Record learning curves on small task (~1min to train)
- Make a tiny code change
- Inspect curves
- Run full training after ~5 tiny changes
[3/4] Downside of ratchet approach is some designs cant be reached via small incremental changes. Also hard to know which tiny code changes to make.
[4/4] Within the ratchet approach, I want more tools and best practices for making feedback loops shorter and for making errors louder.
Below is a short list of development speed hacks that I have found useful.
ML dev speed hack #0 - Overfit a single batch
- Before doing anything else, verify that your model can memorize the labels for a single batch and quickly bring the loss to zero
- This is fast to run, and if the model can’t do this, then you know it is broken
ML dev speed hack #1 - PyTorch over TF
- Time to first step is faster b/c no static graph compilation
- Easier to get loud errors via assertions within the code
- Easier to drop into debugger and inspect tensors
- (TF2.0 may solve some of these problems but is still raw)
ML dev speed hack #2 - Assert tensor shapes
- Wrong shapes due to silent broadcasting or reduction is an extreme hot spot for silent errors, asserting on shapes (in torch or TF) makes them loud
- If you’re ever tempted to write shapes in a comment, make an assert instead
ML dev speed hack #3 - Add ML test to CI
- If more than one entry point or more than one person working on the codebase, then add a test that runs for N steps and then checks loss
- If you only have one person and entry point then an ML test in CI is probably overkill
ML dev speed hack #4 - Use ipdb.set_trace()
- It’s hard to make an ML job take less than 10 seconds to start, which is too slow to maintain flow
- Using the ipdb workflow lets you zero in on a bug and play with tensors with a fast feedback loop
ML dev speed hack #5 - Use nvvp to debug throughput
- ML throughput (step time) is one place where we have the tools to make errors loud and feedback fast
- You can use
torch.cuda.nvtx.range_pushto annotate the nvvp timeline to be more readable
Reference:
- Twitter Thread
- how-i-became-a-machine-learning-practitioner
- Youtube: Troubleshooting Deep Neural Networks - Full Stack Deep Learning
- Youtube: Full Stack Deep Learning