Machine Learning: Natural Language Processing (Part 2)
Content
- Content
- How do you find the similar documents related to some query sentence/search?
- What is POS tagger?
- Learning word sense?
- How would you find all the occurrences of quoted text in a news article?
- Build a system that auto corrects text
- How would you build a system to translate English text to Greek and vice-versa?
- How would you build a system that automatically groups news articles by subject?
- How would you design a model to predict whether a movie review was positive or negative?
- What is Lexicon and Ontology?
- What is
Syntacticanalysis or parsing? - Concept of Parser
- What is
Semanticanalysis? - What is
TaxonomyandOntology? - Explain TF-IDF
- What is word2vec? What is the cost function for skip-gram model(k-negative sampling)?
- TODO: Tf-Idf fails in document classification/clustering? How can you improve further ?
- What are word2vec vectors?
- How can I design a chatbot?
- Exercise
- Question Source
How do you find the similar documents related to some query sentence/search?
- Simplest approach is to do
tf-idfof both documents and query, and then measure cosine distance (i.e., dot product) - On top of that, if you use
SVD/PCA/LSAon thetf-idfmatrix, it should further improve results. - For more on LSI - Latent Semantic Indexing, please check here.
Reference:
What is POS tagger?
A Part-Of-Speech Tagger (POS Tagger) is a piece of software that reads text in some language and assigns parts of speech to each word (and other token), such as noun, verb, adjective, etc.
In POS tagging, the goal is to label a sentence (a sequence of words or tokens) with tags like ADJECTIVE, NOUN, PREPOSITION, VERB, ADVERB, ARTICLE.
For example, given the sentence “Bob drank coffee at Starbucks”, the labeling might be “Bob (NOUN) drank (VERB) coffee (NOUN) at (PREPOSITION) Starbucks (NOUN)”.
How to build a POS simple tagger? How to account for the new word?
Simple Idea:
- First collect tagged sentences
import nltk
tagged_sentences = nltk.corpus.treebank.tagged_sents()
-
Preprocess the sentences and create
[(word_1, tag_1), ... (word_n, tag_n)]. This becomes your $X$ and $Y$. -
Train a multiclass classification algorithm like RandomForest, CRF and build your model
-
Give test sentence, split into words, feed to the model and get corresponding tags.
Reference:
Learning word sense?
Q. How would you train a model that identifies whether the word “Apple” in a sentence belongs to the fruit or the company?
- This is a classic example of
Named Entity Recognition. It is a statistical technique that (most commonly) usesConditional Random Fieldsto find named entities, based on having been trained to learn things about named entities. Essentially, it looks at the content and context of the word, (looking back and forward a few words), to estimate the probability that the word is a named entity.
*In case the above link is broken, click here
For more on Graphical Models, click here
How to build your own NER model?
- It’s a supervised learning problem. So first you need to get labelled data, i.e
wordsandentity_tagpair. For example (London,GEO), (Apple Corp.,ORG) and then train some model. - As a novice model, apply scikit learn multiclass classification algorithm.
- For a more mature model use scikit learn
conditional random fieldtechnique for creating a better model.
Reference:
- named-entity-recognition-and-classification-with-scikit-learn
- training ner with sklearn
- deep learning based NER
- Named Entity Recognition (NER) with keras and tensorflow
How would you find all the occurrences of quoted text in a news article?
Simple Solution
You can do a regex to pick up everything between quotes
list = re.findall("\".*?\"", string)
The problem you’ll run into is that there can be a surprisingly large amount of things between quotation marks that are actually not quotations.
"(said|writes|argues|concludes)(,)? \".?\""
But quotes are a tricky business. Lots of things look like quotes that aren’t, and some things are more quote-like than others. The ideal approach would be able to account for some of that fuzziness in a way that pattern matching doesn’t.
Maximum Entropy Model
empirically consistentwith the training data; and chooses the distribution with thehighest entropy. A probability distribution is “empirically consistent” with a set of training data if its estimated frequency with which a class and a feature vector value co-occur is equal to the actual frequency in the data.
- Many problems in natural language processing can be viewed as
linguistic classificationproblems, in whichlinguistic contextsare used to predictlinguistic classes. -
Maximum entropy models offer a clean way to combine diverse pieces of contextual evidence in order to estimate the probability of a certain
linguistic classoccurring with a certainlinguistic context.
In the above problem, use feature and apply maximum entropy model to classify if a paragraph has quotes or not. (For example, does the paragraph contain an attribution word like “said?")
Reference:
- StackOverflow
- Using machine learning to extract quotes from text
- A Simple Introduction to MaximumEntropy Models for NaturalLanguage Processing
Build a system that auto corrects text
Q. How would you build a system that auto corrects text that has been generated by a speech recognition system?
A spellchecker points to spelling errors and possibly suggests alternatives. An autocorrector usually goes a step further and automatically picks the most likely word. In case of the correct word already having been typed, the same is retained. So, in practice, an autocorrect is a bit more aggressive than a spellchecker, but this is more of an implementation detail — tools allow you to configure the behaviour.
- language-models-spellchecking-and-autocorrection
-
Dan Jurafsky slide

-
Natural Language Corpus Data - Peter Norvig
How would you build a system to translate English text to Greek and vice-versa?
Use seq2seq learning model with attention
How would you build a system that automatically groups news articles by subject?
- Text Classification
- Topic Modelling
Resource:
How would you design a model to predict whether a movie review was positive or negative?
Typically, sentiment analysis for text data can be computed on several levels, including on an individual sentence level, paragraph level, or the entire document as a whole. Often, sentiment is computed on the document as a whole or some aggregations are done after computing the sentiment for individual sentences. There are two major approaches to sentiment analysis.
- Supervised machine learning or deep learning approaches
- Unsupervised lexicon-based approaches
However most of the time we don’t have the labelled data. So let’s go for second approach. Hence, we will need to use unsupervised techniques for predicting the sentiment by using knowledgebases, ontologies, databases, and lexicons that have detailed information, specially curated and prepared just for sentiment analysis.
Various popular lexicons are used for sentiment analysis, including the following.
- AFINN lexicon
- Bing Liu’s lexicon
- MPQA subjectivity lexicon
- SentiWordNet
- VADER lexicon
- TextBlob lexicon
Use these lexicon, convert words to their sentiment
Actually there is no machine learning going on here but this library parses for every tokenized word, compares with its lexicon and returns the polarity scores. This brings up an overall sentiment score for the tweet.
What is Lexicon and Ontology?
-
A
lexiconis a dictionary, vocabulary, or a book of words. In our case, lexicons are special dictionaries or vocabularies that have been created for analyzing sentiments. -
Ontologies provide semantic context. Identifying entities in unstructured text is a picture only half complete. Ontology models complete the picture by showing how these entities relate to other entities, whether in the document or in the wider world.
An ontology is a formal and structural way of representing the concepts and relations of a shared conceptualization

I realize that this sentence is really marked up and there’s arrows and red text going all over the place. So let’s examine this closely.
- We’ve only recognized (e.g.
annotated) two words in this entire sentence: William Shakespeare as a Playwright and Hamlet as a Play. But look at the depth of the understanding that we have. There’s a model depicted on this image, and we want to examine this more carefully. - - You’ll notice first of all that there are a total of 6 annotations represented on the diagram with arrows flowing between them. These annotations are produced by the NLP parser, and modeled (here’s the key point), they are modeled in the Ontology. It’s in the Ontology that we specify how a Book is related to a Date, or to a Language, and a Language to a Country to an Author, to a work produced by that Author, and so on.
- Each annotation is backed by a dictionary. The data for that dictionary is generated out of the triple store that conforms to the Ontology. The Ontology shows the relationship of all the annotations to each other.
Why would someone want to develop an ontology? Some of the reasons are:
- To share common understanding of the structure of information among people or software agents
- To enable reuse of domain knowledge
- To make domain assumptions explicit
- To separate domain knowledge from the operational knowledge
- To analyze domain knowledge

Resource:
What is Syntactic analysis or parsing?
Syntax analysis or syntactic analysis is the process of analysing a string of symbols, either in natural language or in computer languages, conforming to the rules of a formal grammar. The term parsing comes from Latin pars (orationis), meaning part (of speech)
- Syntactic Analysis of a sentence is the task of recognising a sentence and assigning a syntactic structure to it. These syntactic structures are assigned by the Context Free Grammar (mostly PCFG) using parsing algorithms like Cocke-Kasami-Younger (CKY), Earley algorithm, Chart Parser. They are represented in a tree structure. These parse trees serve an important intermediate stage of representation for semantic analysis.
Syntactic Parse Tree
Resource:
Concept of Parser
- It is used to implement the task of parsing. It may be defined as the software component designed for taking input data (text) and giving structural representation of the input after checking for correct syntax as per formal grammar.
- It also builds a data structure generally in the form of parse tree or abstract syntax tree or other hierarchical structure
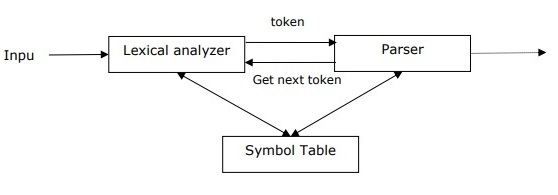
What is Semantic analysis?
We already know that lexical analysis also deals with the meaning of the words, then how is semantic analysis different from lexical analysis? Lexical analysis is based on smaller token but on the other side semantic analysis focuses on larger chunks. That is why semantic analysis can be divided into the following two parts −
- The semantic analysis of natural language content starts by reading all of the words in content to capture the real meaning of any text.
- It identifies the text elements and assigns them to their logical and grammatical role.
-
It analyzes context in the surrounding text and it analyzes the text structure to accurately disambiguate the proper meaning of words that have more than one definition.
- Semantic technology processes the logical structure of sentences to identify the most relevant elements in text and understand the topic discussed.
- It also understands the relationships between different concepts in the text.
- For example, it understands that a text is about “politics” and “economics” even if it doesn’t contain the the actual words but related concepts such as “election,” “Democrat,” “speaker of the house,” or “budget,” “tax” or “inflation.”
Semantic analysis is a larger term, meaning to analyse the meaning contained within text, not just the sentiment. It looks for relationships among the words, how they are combined and how often certain words appear together.
Reference:
What is Taxonomy and Ontology?
An ontology identifies and distinguishes concepts and their relationships; it describes content and relationships.
A taxonomy formalizes the hierarchical relationships among concepts and specifies the term to be used to refer to each; it prescribes structure and terminology. Taxonomy identifies hierarchical relationships within a category.
Ontology
Taxonomy example:
Reference:
Explain TF-IDF
Q. What is the drawback of Tf-Idf ? How do you overcome it ?
Advantages:
- Easy to compute
- You have some basic metric to extract the most descriptive terms in a document
- You can easily compute the similarity between 2 documents using it
Disadvantages:
- TF-IDF is based on the bag-of-words (BoW) model, therefore it does not capture position in text, semantics, co-occurrences in different documents, etc.
- For this reason, TF-IDF is only useful as a lexical level feature
-
Cannot capture semantics (e.g. as compared to topic models, word embeddings)
- link
What is word2vec? What is the cost function for skip-gram model(k-negative sampling)?
TODO: Tf-Idf fails in document classification/clustering? How can you improve further ?
What are word2vec vectors?
Word2Vec embeds words in a lower-dimensional vector space using a shallow neural network. The result is a set of word-vectors where vectors close together in vector space have similar meanings based on context, and word-vectors distant to each other have differing meanings. For example, apple and orange would be close together and apple and gravity would be relatively far. There are two versions of this model based on skip-grams (SG) and continuous-bag-of-words (CBOW).
How can I design a chatbot?
(I had little idea but I tried answering it with intent and response tf-idf based similarity)
Exercise
- Can I develop a chatbot with RNN providing a intent and response pair in input?
- Suppose I developed a chatbot with RNN/LSTMs on Reddit dataset. It gives me 10 probable responses. How can I choose the best reply Or how can I eliminate others replies ?
- How do you perform text classification ?
- How can you make sure to learn a context !! Well its not possible with TF-IDF ?
- I told him about taking n-grams say n = 1, 2, 3, 4 and concatenating tf-idf of them to make a long count vector ? Okay that is the baseline people start with ? What can you do more with machine learning ? (I tried suggesting LSTM with word2vec or 1D-CNN with word2vec for classification but he wanted improvements in machine learning based methods :-|)
- How does neural networks learns non-linear shapes when it is made of linear nodes ? What makes it learn non-linear boundaries ?
- What is the range of sigmoid function ?
- Text classification method. How will you do it ?
- Explain Tf-Idf ?
- What are bigrams & Tri-grams ? Explain with example of Tf-Idf of bi-grams & trigrams with a text sentence.
- What is an application of word2vec ? Example.
- How will you design a neural network ? How about making it very deep ? Very basic questions on neural network.?
- How did you perform language identification ? What were the feature ?
- How did you model classifiers like speech vs music and speech vs non-speech ?
- How can deep neural network be applied in these speech analytics applications ?
Role-specific questions
Natural language processing
- What are stop words? Describe an application in which stop words should be removed.
- How would you design a model to predict whether a movie review was positive or negative?
- Which is a better algorithm for POS tagging – SVM or hidden Markov models?
- What is the difference between shallow parsing and dependency parsing?
- What package are you aware of in python which is used in NLP and ML?
- Explain one application in which stop words should be removed.
- Which is better to use while extracting features character n-grams or word n-grams? Why?
- What is dimensionality reduction?
- Explain the working of SVM/NN/Maxent algorithms
- Which is a better algorithm for POS tagging - SVM or hidden markov models ? why?
- What packages are you aware of in python which are used in NLP and ML?
- What are conditional random fields ?
- When can you use Naive Bayes algorithm for training, what are its advantages and disadvantages?
- How would you build a POS tagger from scratch given a corpus of annotated sentences? How would you deal with unknown words?
Related fields such as information theory, linguistics and information retrieval
- What is entropy? How would you estimate the entropy of the English language?
- What is a regular grammar? Does this differ in power to a regular expression and if so, in what way?
- What is the TF-IDF score of a word and in what context is this useful?
- How does the PageRank algorithm work?
- What is dependency parsing?
- What are the difficulties in building and using an annotated corpus of text such as the Brown Corpus and what can be done to mitigate them?
- Differentiate regular grammar and regular expression.
- How will you estimate the entropy of the English language?
- Describe dependency parsing?
- What do you mean by Information rate?
- Explain Discrete Memoryless Channel (DMC).
- How does correlation work in text mining?
- How to calculate TF*IDF for a single new document to be classified?
- How to build ontologies?
- What is an N-gram in the context of text mining?
- What do you know about linguistic resources such as WordNet?
- Explain the tools you have used for training NLP models?
Tools and languages
- What tools for training NLP models (nltk, Apache OpenNLP, GATE, MALLET etc…) have you used?
- Do you have any experience in building ontologies?
- Are you familiar with WordNet or other related linguistic resources?
- Do you speak any foreign languages?