Machine Learning System Design (Part - 1)
Content
- Content
- Introduction
- Model Deployment
- How to test your machine learning system?
- 12 Factors of reproducible Machine Learning in production
- MLflow and PyTorch — Where Cutting Edge AI meets MLOps
- Practical Deep Learning Systems - Full Stack Deep Learning
- Serve model using Torchserve
Introduction
To learn how to design machine learning systems
I find it really helpful to read case studies to see how great teams deal with different deployment requirements and constraints.
![]()
Model Deployment
Model compression & optimization
Google: Latency 100 -> 400 ms reduces searches 0.2% - 0.6% (2009)
No matter how great your ML models are, if they take just milliseconds too long, users will click on something else.
Fast inference
- Make models faster

- Make models smaller

model_compression ![]() , pruning
, pruning ![]() , factorization
, factorization ![]() ,
,
- Make hardware more
powerful
Simple deployment
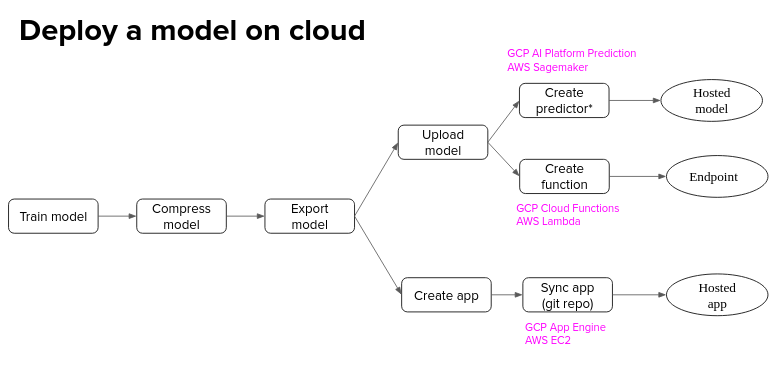
Containerized deployment
- Reduced complexity: each developer works on a smaller codebase
- Faster development cycle: easier review process
- Flexible stack: different microservices can use different technology stacks. Why to use microservice?
- Digging into Docker, Kubernetes, link


Test in production
Canary Testing
- New model alongside existing system
- Some traffic is routed to new model
- Slowly increase the traffic to new model
- E.g. roll out to Vietnam first, then Asia, then rest of the world

A/B testing
- New model alongside existing system
- A percentage of traffic is routed to new model based on routing rules
- Control target audience & monitor any statistically significant differences in user behavior
- Can have more than 2 versions

Shadow test pattern
- New model in parallel with existing system
- New model’s predictions are logged, but not show to users
- Switch to new model when results are satisfactory

Different deployment strategies
Reference:
- CS 329S: Machine Learning Systems Design Winter 2021 - Chip Huyen
-
Application deployment and testing strategies - Google

How to test your machine learning system?
A typical software testing suite will include:
- unit tests which operate on atomic pieces of the codebase and can be run quickly during development,
- regression tests replicate bugs that we’ve previously encountered and fixed,
- integration tests which are typically longer-running tests that observe higher-level behaviors that leverage multiple components in the codebase,
Let’s contrast this with a typical workflow for developing machine learning systems. After training a new model, we’ll typically produce an evaluation report including:
- Performance of an established metric on a validation dataset,
- Plots such as precision-recall curves,
- Operational statistics such as inference speed,
- Examples where the model was most confidently incorrect,
and follow conventions such as:
- Save all of the hyper-parameters used to train the model,
- Only promote models which offer an improvement over the existing model (or baseline) when evaluated on the same dataset.
it feels like that testing for machine learning systems is in such early days that this question of test coverage isn’t really being asked by many people.
Difference between model testing and model evaluation
For machine learning systems, we should be running model evaluation and model tests in parallel.
- Model evaluation covers metrics and plots which summarize performance on a validation or test dataset.
- Model testing involves explicit checks for behaviors that we expect our model to follow.
NOTE: Do error analysis
How do you write model tests?
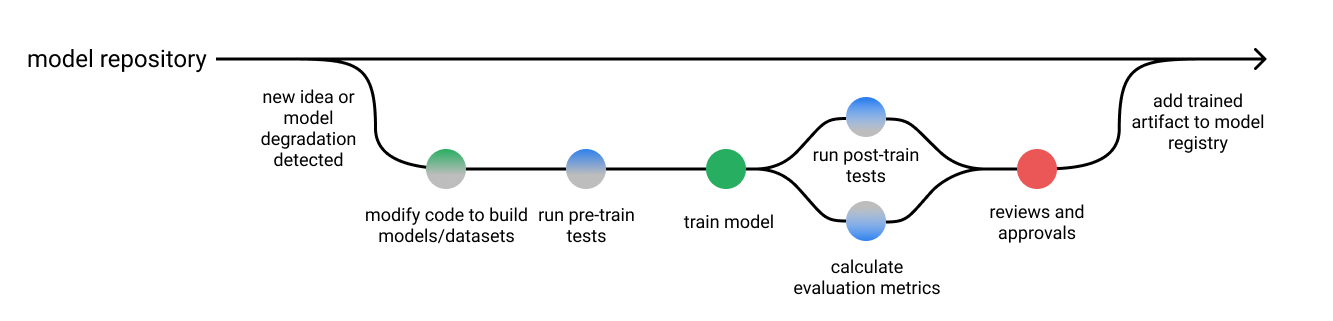
There’s two general classes of model tests that we’ll want to write.
- Pre-train tests allow us to identify some bugs early on and short-circuit a training job.
- Post-train tests use the trained model artifact to inspect behaviors for a variety of important scenarios that we define.
*please read the actual blog thoroughly
- Invariance Tests: check for consistency in the model predictions
-
Directional Expectation Tests: define a set of perturbations to the input which should have a predictable effect on the model output.
- Increasing the number of bathrooms (holding all other features constant) should not cause a drop in price.
- Lowering the square footage of the house (holding all other features constant) should not cause an increase in price.
- Minimum Functionality Tests (aka data unit tests):
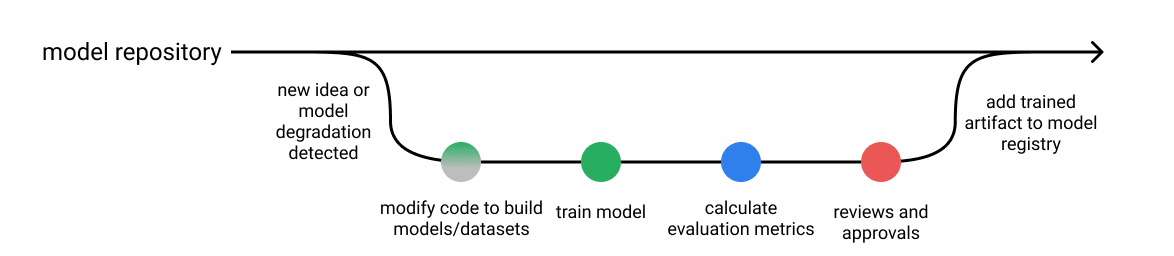
Model development pipeline
Reference:
12 Factors of reproducible Machine Learning in production

- You need to version your code, and you need to version your data.
- Make your feature dependencies explicit in your code
- Write readable code and separate code from configuration.
Code for both preprocessing and models should follow PEP8. It should consist of meaningful object names and contain helpful comments. Following
PEP8will improve code legibility, reduce complexity and speed up debugging. Programming paradigms such asSOLIDprovide thought frameworks to make code more maintainable, understandable and flexible for future use cases.
-
Reproducibility of trainings - Use pipelines and automation.
By using
pipelinesto train models entire teams gain both access and transparency over conducted experiments and training runs. Bundled with areusable codebaseand aseparation from configuration, everyone can successfully relaunch any training at any point in time.
- Test your code, test your models.
-
Drift / Continuous training - If you data can change run a continuous training pipeline
Data monitoring for production systems. Establish automated reporting mechanisms to alert teams of changing data, even beyond explicitly defined feature dependencies Continuous training on newly incoming data. Well-automated pipelines can be rerun on newly recorded data and offer comparability to historic training results to show performance degradation
-
Track results via automation - Weights and Bias
-
Experimentation vs Production models - Notebooks are not production-ready, so experiment in pipelines early on
The earlier you experiment in pipelines, the earlier you can collaborate on intermediate results and the earlier you’ll receive production-ready models
-
Training-Serving-Skew - Correctly embed preprocessing to serving, and make sure you understand up- and downstream of your data
-
Build your pipelines so you can easily compare training results across pipelines.
- Again: you build it, you run it. Monitoring models in production is a part of data science in production
Plenty of negative degradations can occur in the lifecycle of a model: Data can drift, models can become bottlenecks for overall performance and bias is a real issue. Data Scientists and teams are responsible for monitoring the models they produce. At its minimum, a model needs to be monitored for input data, inference times, resource usage (read: CPU, RAM) and output data
- Every training pipeline needs to produce a deployable artefact, not “just” a model
Reference:
MLflow and PyTorch — Where Cutting Edge AI meets MLOps
Full workflow for MLops for building PyTorch models and deploying on the TorchServe plugin using the full MLflow MLops lifecycle management
Practical Deep Learning Systems - Full Stack Deep Learning
Play the video: ![]()
The average elapsed time between key algorithm proposal and corresponding advances was about 18 years, whereas the average elapsed time between key dataset availabilities and corresponding advances was less than 3 years, i.e. about 6 times faster.
- More Data or Better data?
- Simple model » Complex Model
- … but sometime you do need complex model
- We should care about feature engineering
- Deep Learning:
FeatureArchitecture Engineering - Supervised/Unsupervised => Self-Supervised learning
- Everything is ensemble
- There is bias in your data
- Curse of presentation bias
- Bias and Fairness
- Right Evaluation: Offline and Online Experimentation
- ML beyond DL