Machine Learning System Design (Part - 2)
Content
- Content
- How to approach System Design Interview Question
- Design Youtube Recommendation system?
- Design a movie recommendation system like Netflix?
- ML in production
- Production Machine Learning Monitoring: Outliers, Drift, Explainers & Statistical Performance
- System design interview question strategy?
- What is CDN - Content Delivery Network?
- What is Bloom Filter?
- How to design Twitter?
- TODO: How to design a Search Engine ?
- How the Instagram algorithm works in 2019?
- How Does the YouTube Algorithm Work? A Guide to Getting More Views
- How to succeed in a system design interview?
- Recommendation system for Duolingo [@chiphuyen]
- Fraud Detection [@chiphuyen]
- Build a recommendation system to suggest replacement items [@chiphuyen]
- Twitter follower recommendation
- How would you design an algorithm to match pool riders for Lyft or Uber?
- Trigger/Wake word detection, e.g, ‘ok, google!’ [@chiphuyen]
- Click Through Rate (CTR) Prediction
- Design dynamic pricing
How to approach System Design Interview Question
Be familiar with basic knowledge
First of all, there’s no doubt you should be very good at data structure and algorithm. Take the URL shortening service as an example, you won’t be able to come up with a good solution if you are not clear about hash, time/space complexity analysis.
Quite often, there’s a trade-off between time and memory efficiency and you must be very proficient in the big-O analysis in order to figure everything out,
There are also several other things you’d better be familiar although it’s possible that they may not be covered in your interview.
- Abstraction: It’s a very important topic for system design interview. You should be clear about how to abstract a system, what is visible and invisible from other components, and what is the logic behind it. Object oriented programming is also important to know.
- Database: You should be clear about those basic concepts like relational database. Knowing about No-SQL might be a plus depends on your level (new grads or experienced engineers).
- Network: You should be able to explain clearly what happened when you type “gainlo.co” in your browser, things like DNS lookup, HTTP request should be clear.
- Concurrency: It will be great if you can recognize concurrency issue in a system and tell the interviewer how to solve it. Sometimes this topic can be very hard, but knowing about basic concepts like race condition, dead lock is the bottom line.
- Operating system: Sometimes your discussion with the interviewer can go very deeply and at this point it’s better to know how OS works in the low level.
- Machine learning: (optional). You don’t need to be an expert, but again some basic concepts like feature selection, how ML algorithm works in general are better to be familiar with.
 Top-down + modularization
Top-down + modularization
This is the general strategy for solving a system design problem and ways to explain to the interviewer.
![]() The worst case is always jumping into details immediately, which can only make things in a mess.
The worst case is always jumping into details immediately, which can only make things in a mess.
It’s always good to start with high-level ideas and then figure out details step by step, so this should be a top-down approach. Why? Because many system design questions are very general and there’s no way to solve it without a big picture.
You should always have a big picture.
Let’s use Youtube recommendation system as an example. I might first divide this into front-end and backend (the interviewer may only ask for backend or a specific part, but I’ll cover the whole system to give you an idea). For backend, the flow can be 3 steps: collect user data (like videos he watched, location, preferences etc.), offline pipeline that generating the recommendation, and store and serve the data to front-end. And then, we can jump into each detailed components.
Reference:
Design Youtube Recommendation system?
Big Picture:
- Front End
- Back End
- Collect user data (like videos he watched, location, preferences etc.)
- Offline pipeline that generates the recommendation [Hybrid Approach: Heuristic + ML Based]
- Store and Serve the data to front-end.
Basically, we can simplify the system into a couple of major components as follows:
- Storage: How do you design the database schema? What database to use? Videos and images can be a subtopic as they are quite special to store.
- Scalability: When you get millions or even billions of users, how do you scale the storage and the whole system? This can be an extremely complicated problem, but we can at least discuss some high-level ideas.
- Web server: The most common structure is that front ends (both mobile and web) talk to the web server, which handles logics like user authentication, sessions, fetching and updating users’ data, etc.. And then the server connects to multiple backends like video storage, recommendation server and so forth.
- Cache: is another important components. We’ve discussed in details about cache before, but there are still some differences here, e.g. we need cache in multiple layers like web server, video serving, etc..
- There are a couple of other important components like recommendation system, security system and so on. As you can see, just a single feature can be used as a stand-alone interview question.
Storage and data model
If you are using a relational database like MySQL, designing the data schema can be straightforward. And in reality, Youtube does use MySQL as its main database from the beginning and it works pretty well.
First and foremost, we need to define the
-
User model: which can be stored in a single table including email, name, registration data, profile information and so on.- Another common approach is to keep user data in two tables –
-
Authentication Table: For authentication related information like email, password, name, registration date, etc. -
Profile Info Table: Additional profile information like address, age and so forth.
-
- Another common approach is to keep user data in two tables –
-
Video Model: A video contains a lot of information including meta data (title, description, size, etc.), video file, comments, view counts, like counts and so on. Apparently, basic video information should be kept in separate tables so that we can first have a video table. -
Author-Video Table: Another table to mapuser idtovideo id. Anduser-like-videorelation can also be a separate table. The idea here is database normalization – organizing the columns and tables to reduce data redundancy and improve data integrity.
Video and image storage
It’s recommended to store large static files like videos and images separately as it has better performance and is much easier to organize and scale. It’s quite counterintuitive that Youtube has more images than videos to serve. Imagine that each video has thumbnails of different sizes for different screens and the result is having 4X more images than videos. Therefore we should never ignore the image storage.
One of the most common approaches is to use CDN (Content delivery network). In short, CDN is a globally distributed network of proxy servers deployed in multiple data centers. The goal of a CDN is to serve content to end-users with high availability and high performance. It’s a kind of 3rd party network and many companies are storing static files on CDN today.
The biggest benefit using CDN is that CDN replicates content in multiple places so that there’s a better chance of content being closer to the user, with fewer hops, and content will run over a more friendly network. In addition, CND takes care of issues like scalability and you just need to pay for the service.
Popular VS long-tailed videos
If you thought that CDN is the ultimate solution, then you are completely wrong. Given the number of videos Youtube has today ($819,417,600$ hours of video), it’ll be extremely costly to host all of them on CDN especially majority of the videos are long-tailed, which are videos have only $1$-$20$ views a day.
However, one of the most interesting things about Internet is that usually, it’s those long-tailed content that attracts the majority of users. The reason is simple – those popular content can be found everywhere and only long-tailed things make the product special.
Coming back to the storage problem. One straightforward approach is to
- Host popular videos in CDN
- Less popular videos are stored in our own servers by location.
This has a couple of advantages:
- Popular videos are viewed by a huge number of audiences in different locations, which is what CND is good at. It replicates the content in multiple places so that it’s more likely to serve the video from a close and friendly network.
- Long-tailed videos are usually consumed by a particular group of people and if you can predict in advance, it’s possible to store those content efficiently.
Recommendation Architecture:
- Apparently, the system contains multiple steps/components. Which can be divided into
onlineandofflinepart.- e.g. comparing similar users/videos can be time-consuming on Youtube, this part should be done in offline pipelines. For the offline part, all the user models and videos need to store in
distributed systems. - In fact, for most machine learning systems, it’s common to use offline pipeline to process big data as you won’t expect it to finish with few seconds.
- e.g. comparing similar users/videos can be time-consuming on Youtube, this part should be done in offline pipelines. For the offline part, all the user models and videos need to store in
- Feedback loop
- Periodic model training to capture new behavior
ML Algorithm:
-
Colleborative Filtering: In a nutshell, to recommend videos for a user, I can provide videos liked by similar users. For instance, if user A and B have watched a bunch of same videos, it’s highly likely that user A will like videos liked by B. Of course, there are many ways to define what “similar” means here. It could be two users have liked same videos, it could also mean that they share the same location.- The above algorithm is called
user-basedcollaborative filtering. Another version is calleditem-basedcollaborative filtering, which means to recommend videos (items) that are similar to videos a user has watched.
- The above algorithm is called
Locally Sensitive Hashing
Cold Start:
For a new user, based on his/her age, sex, location (available from login information) recommends from a general pool. The genearl pool may contain:
- Most seen/liked videos in the country X
- Most seen/liked videos for the given age, sex
Slowly the user starts to engage with the platform, click some videos, like/dislike some, comment on sime, search some videos. All these activities will help to improve the recommendation system.
The final solution can be a hybrid solution, that is a mixture of Rule Based (Heuristic) and AI based approach.
Heuristic Solution
- Rule based approach
- Based on videos a user has watched, we can simply suggest videos from same authors
- Suggest videos with similar titles or labels.
- If use Popularity (number of comments, shares) as another signal, the recommendation system can work pretty well as a baseline
- Suggest videos whose
titleis similar to thesearch queries
Feature engineering:
Usually, there are two types of features – explicit and implicit features.
- Demographic:
- Age [From Login information]
- Sex [From Login Information]
- Country
-
Explicit features can be
ratings,favoritesetc.. In Youtube, it can be the-
like/share/subscribe actions. - If
do commentfor any video - Video title, label, category
- Time of the day [morning ritual/religious/gym video, evening music video, dance video, party]
- Add videos to
Watch Lateror to explicitUser Playlist
-
-
Implicit features are less obvious.
-
Watch Time: If a user has watched a video for only a couple of seconds, probably it’s a negative sign. -
Personal Preference: Given a list of recommended videos, if a user clicks one over another, it can mean that he prefer to the one clicked. Usually, we need to explore a lot about implicit features. - Freshness [just launched]
-
Recommend from heavy tail
- Under this category the recommendation system will show some diversified content.
Potential Scale Issues:
-
Response time: Offline pipelines to precompute some signals that can speed up the ranking
- Model inference time
-
Scale Architecture: With millions of users, a single server is far from enough due to storage, memory, CPU bound issues etc.. That’s why it’s pretty common to see server crashes when there are a large number of requests. To scale architecture, the rule of thumb is that service-oriented architecture beats monolithic application.
- Instead of having everything together, it’s better to divide the whole system into small components by service and
separate each component. To communicate between different components useload balancer - Cloud Based solution: AWS/Google Cloud/ Azure
- Horizontal Scaling
- Kubernetes based solution
- Instead of having everything together, it’s better to divide the whole system into small components by service and
-
Scale database: Even if we put the database in a separate server, it will not be able to store an infinite number of data. At a certain point, we need to scale the database. For this specific problem, we can either do the
vertical splitting(partitioning) by splitting the database into sub-databases likeuser database,comment databaseetc. orhorizontal splitting(sharding) by splitting based on attributes like US users, European users.
You can check this post for deeper analysis of scalability issues.
Reference:
- Design a Recommendtion System
- Leetcode Discussion
- IJCAI 2013 Tutorial PPT
-
4 Architecture Issues When Scaling Web Applications: Bottlenecks, Database, CPU, IO

Design a movie recommendation system like Netflix?
ML in production
- Deploying ML models is hard :(
- Deploying a model for friends to play with is easy .
- Export trained model, create an endpoint, build a simple app. 30 mins.
- Deploying it reliably is hard. Serving 1000s of requests with ms latency is hard. Keeping it up all the time is hard.
-
You only have a few ML models in production

Booking, eBay have 100s models in prod. Google has 10000s. An app has multiple features, each might have one or multiple models for different data slices.
- You can also serve combos of several models outputs like an ensemble.
-
If nothing happens, model performance remains the same

-
ML models perform best right after training. In prod, ML systems degrade quickly bc of concept drift.
-
 Tip: train models on data generated 6 months ago & test on current data to see how much worse they get.
Tip: train models on data generated 6 months ago & test on current data to see how much worse they get.
-
You won’t need to update your models as much

- One mindboggling fact about DevOps: Etsy deploys 50 times/day. Netflix 1000s times/day. AWS every 11.7 seconds.
- MLOps isn’t an exemption. For online ML systems, you want to update them as fast as humanly possible.
-
Deploying ML systems isn’t just about getting ML systems to the end-users

- It’s about building an infrastructure so the team can be quickly alerted when something goes wrong, figure out what went wrong, test in production, roll-out/rollback updates.
It’s fun! ![]()
Reference:
Production Machine Learning Monitoring: Outliers, Drift, Explainers & Statistical Performance
*In case the above link is broken, click here
ML Performance monitoring
- prometheus grafana
- Seldon Core
- Monitoring Machine Learning Models in Production
Reference:
System design interview question strategy?
- Define the problem
- High level design only
- Tackle from different angle
- Scale
- Latency
- Response time
- Database management
- …
Formal Way:
- Step 1 — Understand the Goals
- What is the goal of the system?
- Who are the users of the system? What do they need it for? How are they going to use it?
- What are the inputs and outputs of the system?
- Step 2 — Establish the Scope [Ask clarifying questions, such as:]
- Do we want to discuss the end-to-end experience or just the API?
- What clients do we want to support (mobile, web, etc)?
- Do we require authentication? Analytics? Integrating with existing systems?
- Step 3 — Design for the Right Scale
- What is the expected read-to-write ratio?
- How many concurrent requests should we expect?
- What’s the average expected response time?
- What’s the limit of the data we allow users to provide?
- Step 4 — Start High-Level, then Drill-Down
- User interaction
- External API calls
- Offline processes
- Step 5 — Data Structures and Algorithms (DS&A)
- URL shortener? Makes me think of a hashing function.
- Oh, you need it to scale? Sharding might help
- Concurrency?
- Redundancy?
- Generating keys becomes even more complicated.
- Step 6 — Tradeoffs
- What type of database would you use and why?
- What caching solutions are out there? Which would you choose and why?
- What frameworks can we use as infrastructure in your ecosystem of choice?
Technology to focus
- Horizontal Scaling
- Vertical Scaling
- Intelligent Caching
- Database:
-
NoSQL
-
Key Value Pair Based: Key value stores help the developer to store schema-less data. They work best for
shopping cart contents. Redis,Dynamo,Riakare some examples of key-value store DataBases. They are all based on Amazon’s Dynamo paper. -
Column-based: Column-based NoSQL databases are widely used to manage
data warehouses, business intelligence, CRM, Library card catalogs. HBase,Cassandra, HBase, Hypertable -
Document-Oriented: The document type is mostly used for CMS systems,
blogging platforms, real-time analytics &e-commerce applications. Amazon SimpleDB, CouchDB,MongoDB, Riak, Lotus Notes, MongoDB -
Graph-Based: Graph base database mostly used for
social networks, logistics,spatial data. Neo4J, Infinite Graph,OrientDB, FlockDB.
-
Key Value Pair Based: Key value stores help the developer to store schema-less data. They work best for
-
NoSQL
Algorithm to Focus:
- Ranking Algorithm
- Searching Algorithm
- Similarity Score
- Recommendation Algo
Resource:
What is CDN - Content Delivery Network?
A content delivery network, or content distribution network (CDN), is a geographically distributed network of proxy servers and their data centers. The goal is to provide high availability and performance by distributing the service spatially relative to end users.

CDNs are a layer in the internet ecosystem. Content owners such as media companies and e-commerce vendors pay CDN operators to deliver their content to their end users. In turn, a CDN pays Internet service providers (ISPs), carriers, and network operators for hosting its servers in their data centers.
CDN is an umbrella term spanning different types of content delivery services: video streaming, software downloads, web and mobile content acceleration, licensed/managed CDN, transparent caching, and services to measure CDN performance, load balancing, Multi CDN switching and analytics and cloud intelligence. CDN vendors may cross over into other industries like security, with DDoS protection and web application firewalls (WAF), and WAN optimization.
Reference:
What is Bloom Filter?
A Bloom filter is a space-efficient probabilistic data structure, conceived by Burton Howard Bloom in 1970, that is used to test whether an element is a member of a set.
- False positive matches are possible
- False negatives are not
A query returns either possibly in set or definitely not in set. Elements can be added to the set, but not removed (though this can be addressed with the counting Bloom filter variant); the more items added, the larger the probability of false positives.
Reference:
How to design Twitter?
Define Problem:
- Data modeling.
- Data modeling – If we want to use a relational database like
MySQL, we can defineuser objectandfeed object. Two relations are also necessary. One is user can follow each other, the other is each feed has a user owner.
- Data modeling – If we want to use a relational database like
- How to serve feeds.
- The most straightforward way is to fetch feeds from all the people you follow and render them by time.
Follow Up question
- When users followed a lot of people, fetching and rendering all their feeds can be costly. How to improve this?
- There are many approaches. Since Twitter has the infinite scroll feature especially on mobile, each time we only need to
fetch the most recent Nfeeds instead of all of them. Then there will many details about how thepaginationshould be implemented. - Use
cacheto store most recent stuff to reduce fetching time
- How to detect fake users?
- This can be related to machine learning. One way to do it is to identify several related features like
registration date, thenumber of followers, thenumber of feedsetc. and build a machine learning system to detect if a user is fake. - Check for pattern like how for a reglar user their number of followers and number of feeds grow over time. For a regular user the growth is monotonic but generally Fake user gains lots of followers and contents in a short span [excluding true celibrity, who if joined, on day 1 will get million followers]
Can we order feed by other algorithms? Relevency and Recency algorithm
There are a lot of debate about this topic over the past few weeks. If we want to order based on users interests, how to design the algorithm?
Facebook, is ranked by relevance
Relevance Ranking: Relevancy ranking is the method that is used to order the results list in such a way that the records most likely to be of interest to a user will be at the top. This makes searching easier for users as they won’t have to spend as much time looking through records for the information that interests them. A good ranking algorithm will put information most relevant to a user’s query at the beginning of the returned results.
How does relevancy ranking algorithms work?
Some factors/features:
- The number of times the search term occurs within a given record.
- The number of times the search term occurs across the collection of records.
- The number of words within a record.
- The frequencies of words within a record.
- The number of records in the index.
How does recency ranking algorithms work?
According to Instagram, back when feeds were organized in
reverse-chronological order,i.e using recency, Instagram estimates people missed 50 percent of those important posts, and 70 percent of their feed overall.
Resource
TODO: How to design a Search Engine ?
How the Instagram algorithm works in 2019?
Instagram’s primary goal is to maximize the time users spend on the platform. Because the longer users linger, the more ads they see. So directly or indirectly, accounts that help Instagram achieve that goal are rewarded.
How the algorithm uses ranking signals to decide how to arrange each individual user’s feed.
- Relationship
- Instagram’s algorithm prioritizes content from accounts that users interact with a lot, (commenting each other, DM each other, tag each others post)
- Interest:
- Algorithm also predicts which posts are important to users based on their past behaviour. Potentially includes the use of machine vision (a.k.a. image recognition) technology to assess the content of a photo.
- Timeliness (Recency)
- For brands, the timeliness (or “recency”) ranking signal means that paying attention to your audience’s behaviour, and posting when they’re online, is key.
Resource:
How Does the YouTube Algorithm Work? A Guide to Getting More Views
Features for the algorithm:
- what people watch or don’t watch (a.k.a. impressions vs plays)
- how much time people spend watching your video (watch time, or retention)
- how quickly a video’s popularity snowballs, or doesn’t (view velocity, rate of growth)
- how new a video is (new videos may get extra attention in order to give them a chance to snowball)
- how often a channel uploads new video
- how much time people spend on the platform (session time)
- likes, dislikes, shares (engagement)
- ‘not interested’ feedback (ouch)
Resource:
How to succeed in a system design interview?
Recommendation system for Duolingo [@chiphuyen]
Question: Duolingo is a platform for language learning. When a student is learning a new language, Duolingo wants to recommend increasingly difficult stories to read.
- How would you measure the difficulty level of a story?
- Given a story, how would you edit it to make it easier or more difficult?
Answer:
Prologue: This problem can be mapped to predict Text Readability.
The RAND Reading Study Group (2002:25), a 14-member panel funded by the United States Department of Education’s Office of Educational Research and Improvement, propose the following categories and dimensions that vary among texts and create varying challenges for readers:
- discourse genre, such as narration, description, exposition, and persuasion;
- discourse structure, including rhetorical composition and coherence;
- media forms, such as textbooks, multimedia, advertisements, and the Internet;
- Sentence difficulty, including vocabulary, syntax, and the propositional text base;
- content, such as age-appropriate selection of subject matter;
- texts with varying degrees of engagement for particular classes of readers.
A text can introduce different level of complexity
Lexical and syntactic complexity
The best estimate of a text’s difficulty involved the use of eight elements:
- Number of different hard words
- Number of easy words
- Percentage of monosyllables
- Number of personal pronouns
- Average sentence length in words
- Percentage of different words
- Number of prepositional phrases
- Percentage of simple sentences
These are all structural elements in the style group, as they “lend themselves most readily to quantitative enumeration and statistical treatment
Content and subject matter
In terms of content and subject matter, it is commonly believed that abstract texts (e.g., philosophical texts) will be harder to understand than concrete texts describing real objects, events or activities (e.g., stories), and texts on everyday topics are likely to be easier to process than those that are not (Alderson 2000:62).
How to measure Text Readability?
To measure text difficulty, reading researchers have tended to focus on developing readability formulas since the early 1920s. A readability formula is an equation which combines the statistically measurable text features that best predict text difficulty, such as:
- average sentence length in words or in syllables,
- average word length in characters
- percentage of difficult words (i.e., words with more than two syllables, or words not on a particular wordlist)
Until the 1980s, more than 200 readability formulas had been published (Klare 1984). Among them, the Flesch Reading Ease Formula, the Dale–Chall Formula, Gunning Fog Index, the SMOG Formula, the Flesch–Kincaid Readability test, and the Fry Readability Formula are the most popular and influential (DuBay 2004). These formulas use one to three factors with a view to easy manual application.
Among these factors, vocabulary difficulty (or semantic factors) and sentence length (or syntactic factors) are the strongest indexes of readability (Chall and Dale 1995). The following is the Flesch Reading Ease Formula.
The resulting score ranges from 0 to 100; the lower the score, the more difficult to read the material.
Final Solution:
Q1. How would you measure the difficulty level of a story?
- Given a story, process it to get all the features related to Syntactic or Structural complexities as mentioned above.
- Then for all the sotries $S_i$ we have such feature vector $f_i$.
- Apply clustering technique on all the data points over the feature space.
- Now for each data point inside the cluster, measure their
readability scoreas per the formula mentioned above and rank the stories inside each cluster by sorting. - Also calculate the
mean readability scorefor each cluster and rank the clusters (via sorting) as well. - now pick the cluster with minimum mean readability score and randomly pick $k$ stories and recommend the user one after another. After the user finishes the $k$ stories from the cluster $C_i$, pick the next tougher cluster $C_{i+1}$ and pick $K$ stories again.
- Also keep a liked/disliked or easy/medium/hard check box for each story to get user feedback after he finished the story. These feedbacks can be passed as feedback loop and can be combined with the existing recommendation system.
Q2. Given a story, how would you edit it to make it easier or more difficult?
- Modify the structural complexities.
- Refactor the content to introduce more simple sentence, Easy synonyms, inject more words with mono syllables etc.
Resource:
Fraud Detection [@chiphuyen]
Given a dataset of credit card purchases information, each record is labelled as fraudulent or safe, how would you build a fraud detection algorithm?
Decision Tree based approach:
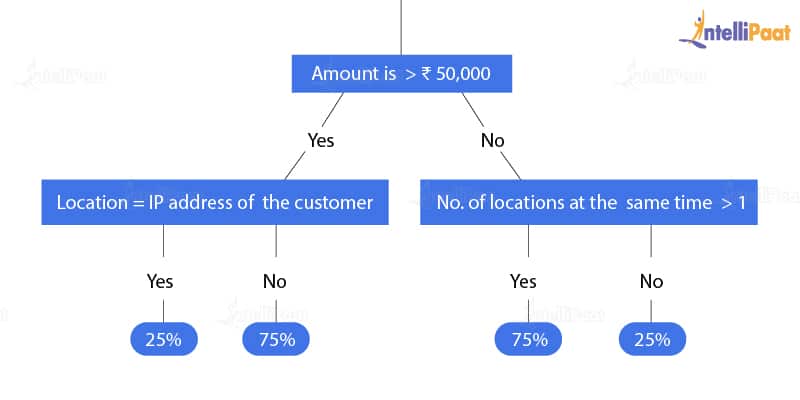
First, in the decision tree, we will check whether the transaction is greater than ₹50,000. If it is ‘yes,’ then we will check the location where the transaction is made.
And if it is ‘no,’ then we will check the frequency of the transaction.
After that, as per the probabilities calculated for these conditions, we will predict the transaction as ‘fraud’ or ‘non-fraud.’
Here, if the amount is greater than ₹50,000 and location is equal to the IP address of the customer, then there is only a 25 percent chance of ‘fraud’ and a 75 percent chance of ‘non-fraud.’
Similarly, if the amount is greater than ₹50,000 and the number of locations is greater than 1, then there is a 75 percent chance of ‘fraud’ and a 25 percent chance of ‘non-fraud.’
Main challenges involved in credit card fraud detection are:
- Enormous Data is processed every day and the model build must be fast enough to respond to the scam in time.
- Imbalanced Data i.e most of the transactions(99.8%) are not fraudulent which makes it really hard for detecting the fraudulent ones
- Data availability as the data is mostly private.
- Misclassified Data can be another major issue, as not every fraudulent transaction is caught and reported.
- Adaptive techniques used against the model by the scammers.
Reference:
- Class Imbalance Python
- Credit-Card-Fraud-Detection-in-python-using-scikit-learn
- practical-guide-deal-imbalanced-classification-problems
- fraud-detection-machine-learning-algorithms
- Check location of an IP address
Build a recommendation system to suggest replacement items [@chiphuyen]
Question: You run an e-commerce website. Sometimes, users want to buy an item that is no longer available. Build a recommendation system to suggest replacement items.
- Do a Nearest Neighbor Search for all the items those are similar to the original item and recommend those as replacement.
Twitter follower recommendation
Question: For any user on Twitter, how would you suggest who they should follow? What do you do when that user is new? What are some of the limitations of data-driven recommender systems?
- search for Similar bio of the twitter handle and suggest them.
How would you design an algorithm to match pool riders for Lyft or Uber?
Design Decisions
In the initial design of Line,
- passengers would enter in their origin and destination,
- receive a fare for the ride
- be put in the matching pool for 1 minute before being assigned a driver.
- If we didn’t find a good match at the end of that minute, we’d still dispatch a driver to the passenger
Naive Matching
-
Haversine matchmaking system:
- Haversine distances $d_{hvrsn}(A,B)$ are straight-line distances between two points A, B and are multiplied by the region’s (pink box, $region(A,B)$) average speed $\mu_v$ to get a time estimate $t_{AB}$
- A greedy system is one in which we take the first match we find that satisfies our constraints, as opposed to the best one for the entire system.
- We denoted passengers as letters of the alphabet and every passenger has two stops — a pickup and drop-off — A and A’, B and B’, etc. So when comparing passenger A and B, we looked at 24 potential orderings: ABB’A’, ABA’B’, B’A’BA, B’AA’B, B’ABA’, BAA’B’, AA’B’B, B’BAA’, etc. We were able to reduce the number of permutations down to only 4 given that there would never be a drop-off before a pickup, and an ordering such as AA’BB’ had no overlap and thus wasn’t worth considering. We would look at all four permutations and eliminate ones that didn’t satisfy all of our constraints. We would then choose the most optimal ordering.
-
Optimal Ordering: The most optimal ordering is the one in which the
total matched distance is minimized. For example if an ABBA route had a total distance of 3.5 miles, but an ABAB route had a total distance of 3.2 miles, we would select the ABAB route.
def make_matches(all_rides):
for r1 in all_rides:
for r2 in all_rides:
orderings = []
for ordering in get_permutations(r1, r2):
if is_good_match(r1, r2, ordering):
orderings.append(ordering)
best_ordering = get_best_ordering(r1, r2, orderings)
if best_ordering:
make_match(r1, r2, best_ordering)
# etc ...
Improvement
- We needed to get away from using haversine estimates as they were just too inaccurate:
- Haversine algorithm would probably be matching passengers on opposite sides of the mountain.
- We considered
building a routing graphand using the A* algorithm, similar to Open Source Routing Machine - OSRM and something we had done for our pricing estimates, but we knew it wouldn’t scale in our $O(n^2)$ algorithm without an investment in offline computational techniques like contraction hierarchies and a lot of work on building a scalable system
GeoHash based model
Geohash is a public domain geocode system invented, which
- Encodes a geographic location into a short string of letters and digits.
- Geohashing is a technique for bucketing latitude and longitude coordinates
- It is a hierarchical spatial data structure which subdivides space into buckets of grid shape
- Geohashes offer properties like arbitrary precision and the possibility of gradually removing characters from the end of the code to reduce its size (and gradually lose precision). As a consequence of the gradual precision degradation, nearby places will often (but not always) present similar prefixes. The longer a shared prefix is, the closer the two places are.
Using historical data from past Lyft rides, we could record the average speed $\mu_v$ of our rides from one geohash $h_{geo}(A)$ to another $h_{geo}(B)$ and store that in a simple hash-table lookup. Then, when calculating estimates, we would multiply the haversine distance $d_{hvrsn}(A,B)$ between those two points with this speed to figure out a time estimate $t_{AB}$
- Added another nested hash table for
each hourof the week between origin and destination which reduced our inaccuracies around rush hour. - This approach also became more accurate as we collected more data as we could break our model down into smaller geohash sizes.
Efficiency and Efficiency improvements
Triple matching ABCBCA or even ABACBDCD, adding up to a total of $1,776$ permutations. This meant we had to quickly scale the efficiency of our system to handle this load
- Longitudinal Sorting: When considering pairing A and B together, there was some maximum distance they could be apart from each other. So we sorted the outer and inner loops by longitude, we could short circuit out of that loop when we’ve passed this maximum distance.
The Road to Becoming Less Greedy
- Our greedy algorithm was built to find
a match, and we made the first match that came along. We instead had to find thebest possible match. This included considering all riders in our system in addition to predicting future demand.
- For those interested in Algorithms, this became something of a maximum matching problem for a
weighted graphcombined with elements of a Secretary Problem. The optimal solution would combine an accurate prediction of future demand with an algorithm that optimized for all possible matches before making any one.
Constraints
- For a match to be made, the total detour that match added for each passenger would have to be below an absolute threshold, but would also have to be below a proportional threshold.
- This makes sense as one can imagine a 5 minute detour is much more tolerable on a 30 minute ride than on a 5 minute ride
- We had similar constraints for additional time until passengers were picked up.
- We started learning that passengers didn’t want to go backwards, and in fact the angle of the lines they saw on the map would affect their satisfaction with the match.
- Users would often rather have a 10 min detour that had no backtracking then a 5 minute detour with backtracking.
- We also learned that people would rather have a short pick up time and long detour than vice versa
- Triple matching ABCBCA or even ABACBDCD, adding up to a total of 1,776 permutations. This meant we had to quickly scale the efficiency of our system to handle this load
- One of our constraints for making a good match was the time it took for a passenger to be picked up. If it took 15 minutes to get picked up, it didn’t matter how fast the rest of the route was — passengers wouldn’t consider that an acceptable route. This meant that when considering pairing A and B together, there was some maximum distance they could be apart from each other.
Challenges
- Finding drivers for all of our passengers at the same time would add a supply shock to our system as we’d need to have a pool of drivers available on the ten minute mark
- The initial implementation compared every passenger with every other passenger in the system $O(n^2)$, in all possible orderings.
Resource
Meta-knowledge
Maximum Matching

In the mathematical discipline of graph theory, a matching or independent edge set in a graph is a set of edges without common vertices. Finding a matching in a bipartite graph can be treated as a network flow problem. A maximum matching (also known as maximum-cardinality matching) is a matching that contains the largest possible number of edges. There may be many maximum matchings.
Secretary Problem
The secretary problem is a problem that demonstrates a scenario involving optimal stopping theory.
The basic form of the problem is the following: imagine an administrator who wants to hire the best secretary out of $n$ rankable applicants for a position. The applicants are interviewed one by one in random order. A decision about each particular applicant is to be made immediately after the interview. Once rejected, an applicant cannot be recalled. During the interview, the administrator gains information sufficient to rank the applicant among all applicants interviewed so far, but is unaware of the quality of yet unseen applicants. The question is about the optimal strategy (stopping rule) to maximize the probability of selecting the best applicant. If the decision can be deferred to the end, this can be solved by the simple maximum selection algorithm of tracking the running maximum (and who achieved it), and selecting the overall maximum at the end. The difficulty is that the decision must be made immediately.
A* Algorithm
A* is an informed search algorithm, or a best-first search, meaning that it is formulated in terms of weighted graphs: starting from a specific starting node of a graph, it aims to find a path to the given goal node having the smallest cost (least distance travelled, shortest time, etc.).
It does this by maintaining a tree of paths originating at the start node and extending those paths one edge at a time until its termination criterion is satisfied.
At each iteration of its main loop, A* needs to determine which of its paths to extend. It does so based on the cost of the path and an estimate of the cost required to extend the path all the way to the goal. Specifically, A* selects the path that minimizes
where
- $n$ is the next node on the path
- $g(n)$ is the cost of the path from the start node to $n$
- $h(n)$ is a heuristic function that estimates the cost of the cheapest path from n to the goal
Contraction Hierarchies
In computer science, the method of contraction hierarchies is a speed-up technique for finding the shortest-path in a graph. The most intuitive applications are car-navigation systems: A user wants to drive from A to B using the quickest possible route. The metric optimized here is the travel time. Intersections are represented by vertices, the street sections connecting them by edges. The edge weights represent the time it takes to drive along this segment of the street.
A path from A to B is a sequence of edges (streets); the shortest path is the one with the minimal sum of edge weights among all possible paths. The shortest path in a graph can be computed using Dijkstra’s algorithm; but given that road networks consist of tens of millions of vertices, this is impractical.
Contraction hierarchies is a speed-up method optimized to exploit properties of graphs representing road networks. The speed-up is achieved by creating shortcuts in a preprocessing phase which are then used during a shortest-path query to skip over unimportant vertices. This is based on the observation that road networks are highly hierarchical. Some intersections, for example highway junctions, are “more important” and higher up in the hierarchy than for example a junction leading into a dead end. Shortcuts can be used to save the precomputed distance between two important junctions such that the algorithm doesn’t have to consider the full path between these junctions at query time. Contraction hierarchies do not know about which roads humans consider “important” (e.g. highways), but they are provided with the graph as input and are able to assign importance to vertices using heuristics.
Trigger/Wake word detection, e.g, ‘ok, google!’ [@chiphuyen]
Question: How would you build a trigger word detection algorithm to spot the word “activate” in a 10 second long audio clip?
Click Through Rate (CTR) Prediction
Design dynamic pricing
- Traditional price management methods almost never achieve optimal pricing because they are designed for traditional environments, where the frequency of price changes is inherently limited (e.g., brick-and-mortar stores), and the complexity of pricing models is constrained by the capabilities of off-the-shelf tools and manual processes.
- Dynamic pricing algorithms help to increase the quality of pricing decisions in e-commerce environments by leveraging the ability to change prices frequently and collect the feedback data in real time.
Overview
Traditional price optimization requires knowing or estimating the dependency between the price and demand. Assuming that this dependency is known (at least at a certain time interval), the revenue-optimal price can be found by employing the following equation:
where $p$ is the price and $d(p)$ is a demand function.
The traditional price management process assumes that the demand function is estimated from the historical sales data, that is, by doing some sort of regression analysis for observed pairs of prices and corresponding demands $(p_i,d_i)$.
- Since the price-demand relationship changes over time, the traditional process typically re-estimates the demand function on a regular basis.
Challenge
The fundamental limitation of this approach is that it passively learns the demand function without actively exploring the dependency between the price and demand. This may or may not be a problem depending on how dynamic the environment is:
- If the product life cycle is relatively long and the demand function changes relatively slowly, the passive learning approach combined with organic price changes can be efficient, as the price it sets will be close to the true optimal price most of the time.
- If the product life cycle is relatively short or the demand function changes rapidly, the difference between the price produced by the algorithm and the true optimal price can become significant, and so will the lost revenue. In practice, this difference is substantial for many online retailers, and critical for retailers and sellers that extensively rely on short-time offers or flash sales (Groupon, Rue La La, etc.).
Constraints
Classical exploration-exploitation problem:
- Minimize the time spent on testing different price levels and collecting the corresponding demand points to accurately estimate the demand curve
- Maximize the time used to sell at the optimal price calculated based on the estimate
- Optimize the exploration-exploitation trade-off given that the seller does not know the demand function in advance
- Provide the ability to limit the number of price changes during the product life cycle.
- Provide the ability to specify valid price levels and price combinations. Most retailers restrict themselves to a certain set of price points (e.g., $25.90, $29.90, …, $55.90), and the optimization process has to support this constraint.
- Enable the optimization of prices under inventory constraints, or given dependencies between products.
Reference