Survey - GAN
Content
- Content
- Understanding Generative Adversarial Networks
- Implementation
- What are the GAN Problems
- What is Mode Collapse? [asked in DL interview]
- Why GAN for text is difficult?
Understanding Generative Adversarial Networks
From the author of GAN:
GANs work by training a generator network that outputs synthetic data, then running a discriminator network on the synthetic data. The gradient of the output of the discriminator network with respect to the synthetic data tells you how to slightly change the synthetic data to make it more realistic.
A GAN is comprised of two neural networks —
- Generator that synthesizes new samples from scratch
- Discriminator that compares training samples with these generated samples from the generator.
The discriminator’s goal is to distinguish between real and fake inputs (ie. classify if the samples came from the model distribution or the real distribution). As we described, these samples can be images, videos, audio snippets, and text.

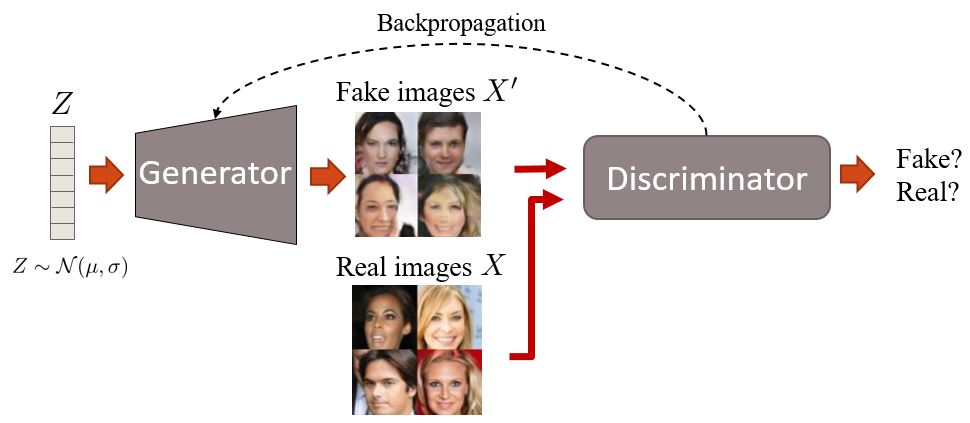
- At first, the generator generates images. It does this by sampling a vector noise $Z$ from a simple distribution (e.g. normal) and then upsampling this vector up to an image. In the first iterations, these images will look very noisy.
- Then, the discriminator is given fake and real images and learns to distinguish them.
- The generator later receives the “feedback” of the discriminator through a backpropagation step, becoming better at generating images.
- At the end, we want that the distribution of fake images is as close as possible to the distribution of real images. Or, in simple words, we want fake images to look as plausible as possible.
It is worth mentioning that due to the minimax optimization used in GANs, the training might be quite unstable. There are some hacks, though, that you can use for a more robust training.







Reference:
- Blog
- GAN implementation
- Fantastic-GANs-and-where-to-find-them
- Introduction to Generative Adversarial Networks (GANs):
- Stanford Slide
Implementation
There are really only 5 components to think about:
- R: The original, genuine data set
In our case, we’ll start with the simplest possible R — a bell curve. This function takes a mean and a standard deviation and returns a function which provides the right shape of sample data from a Gaussian with those parameters.

- I: The random noise that goes into the generator as a source of entropy
The input into the generator is also random, but to make our job a little bit harder, let’s use a uniform distribution rather than a normal one. This means that our model G can’t simply shift/scale the input to copy R, but has to reshape the data in a non-linear way.

- G: The generator which tries to copy/mimic the original data set
The generator is a standard feedforward graph — two hidden layers, three linear maps. We’re using a hyperbolic tangent activation function ‘cuz we’re old-school like that. G is going to get the uniformly distributed data samples from I and somehow mimic the normally distributed samples from R — without ever seeing R.

- D: The discriminator which tries to tell apart G’s output from R
The discriminator code is very similar to G’s generator code; a feedforward graph with two hidden layers and three linear maps. The activation function here is a sigmoid — nothing fancy, people. It’s going to get samples from either R or G and will output a single scalar between 0 and 1, interpreted as ‘fake’ vs. ‘real’. In other words, this is about as milquetoast as a neural net can get.

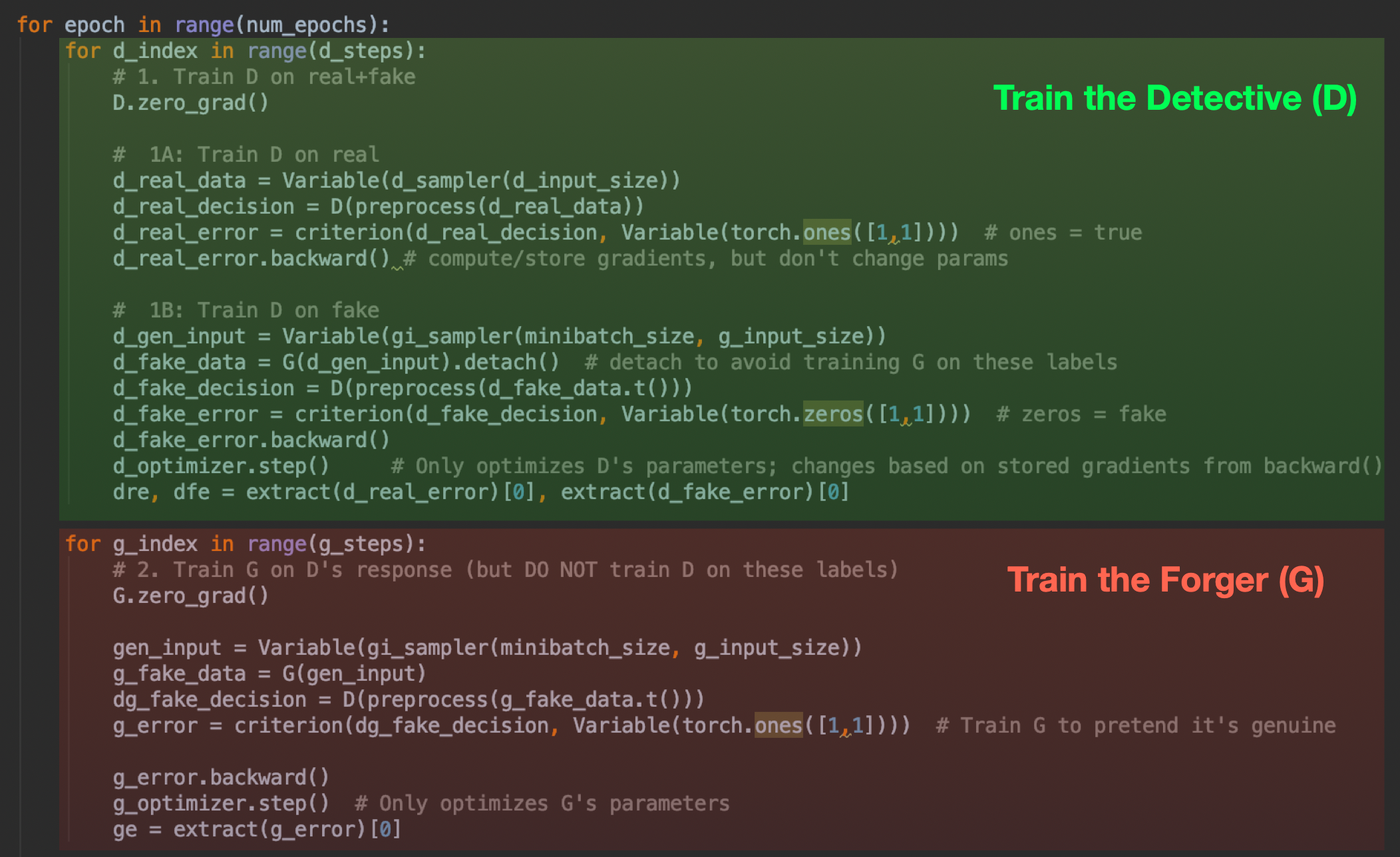
- The actual ‘training’ loop where we teach G to trick D and D to beware G.
Finally, the training loop alternates between two modes: first training D on real data vs. fake data, with accurate labels (think of this as Police Academy); and then training G to fool D, with inaccurate labels (this is more like those preparation montages from Ocean’s Eleven). It’s a fight between good and evil, people.
Reference:
What are the GAN Problems
Many GAN models suffer the following major problems:
- Non-convergence: the model parameters oscillate, destabilize and never converge,
- Mode collapse: the generator collapses which produces limited varieties of samples,
- Diminished gradient: the discriminator gets too successful that the generator gradient vanishes and learns nothing,
- Unbalance between the generator and discriminator causing overfitting
- Highly sensitive to the hyperparameter selections.
Reference:
What is Mode Collapse? [asked in DL interview]
EASY ANSWER
Real-life data distributions are multimodal. For example, in MNIST, there are 10 major modes from digit ‘0’ to digit ‘9’. The samples below are generated by two different GANs. The top row produces all 10 modes while the second row creates a single mode only (the digit “6”). This problem is called mode collapse when only a few modes of data are generated.

Usually you want your GAN to produce a wide variety of outputs. You want, for example, a different face for every random input to your face generator.
However, if a generator produces an especially plausible output, the generator may learn to produce only that output. In fact, the generator is always trying to find the one output that seems most plausible to the discriminator.
If the generator starts producing the same output (or a small set of outputs) over and over again, the discriminator’s best strategy is to learn to always reject that output. But if the next generation of discriminator gets stuck in a local minimum and doesn’t find the best strategy, then it’s too easy for the next generator iteration to find the most plausible output for the current discriminator.
Each iteration of generator over-optimizes for a particular discriminator, and the discriminator never manages to learn its way out of the trap. As a result the generators rotate through a small set of output types. This form of GAN failure is called mode collapse.
Attempts to Remedy
The following approaches try to force the generator to broaden its scope by preventing it from optimizing for a single fixed discriminator:
- Wasserstein loss: The Wasserstein loss alleviates mode collapse by letting you train the discriminator to optimality without worrying about vanishing gradients. If the discriminator doesn’t get stuck in local minima, it learns to reject the outputs that the generator stabilizes on. So the generator has to try something new.
- Unrolled GANs: Unrolled GANs use a generator loss function that incorporates not only the current discriminator’s classifications, but also the outputs of future discriminator versions. So the generator can’t over-optimize for a single discriminator.
ADVANCE ANSWER: Follow this blog.
Reference:
Why GAN for text is difficult?
The author gave his response in this reddit post
Directly copying from there.
GANs have not been applied to NLP because GANs are only defined for real-valued data.
GANs work by training a generator network that outputs synthetic data, then running a discriminator network on the synthetic data. The gradient of the output of the discriminator network with respect to the synthetic data tells you how to slightly change the synthetic data to make it more realistic.
You can make slight changes to the synthetic data only if it is based on continuous numbers. If it is based on discrete numbers, there is no way to make a slight change.
For example, if you output an image with a pixel value of $1.0$, you can change that pixel value to $1.0001$ on the next step.
If you output the word penguin, you can’t change that to penguin + .001 on the next step, because there is no such word as penguin + .001. You have to go all the way from penguin to ostrich.
Since all NLP is based on discrete values like words, characters, or bytes, no one really knows how to apply GANs to NLP yet.
In principle, you could use the REINFORCE algorithm, but REINFORCE doesn’t work very well, and no one has made the effort to try it yet as far as I know.
I see other people have said that GANs don’t work for RNNs. As far as I know, that’s wrong; in theory, there’s no reason GANs should have trouble with RNN generators or discriminators. But no one with serious neural net credentials has really tried it yet either, so maybe there is some obstacle that comes up in practice.
BTW, VAEs work with discrete visible units, but not discrete hidden units (unless you use REINFORCE, like with DARN/NVIL). GANs work with discrete hidden units, but not discrete visible units (unless, in theory, you use REINFORCE). So the two methods have complementary advantages and disadvantages.
**please read the comment section of the said reddit post. Lots of interesting insight.