Survey - Data Programming
Content
- Content
- Snorkel: Rapid Training Data Creation with Weak Supervision
- Data Programming: Creating Large Training Sets, Quickly
Snorkel: Rapid Training Data Creation with Weak Supervision
What is Weak Supervision
According to this bolg
Noisier or higher-level supervision is used as a more expedient and flexible way to get supervision signal, in particular from subject matter experts (SMEs).
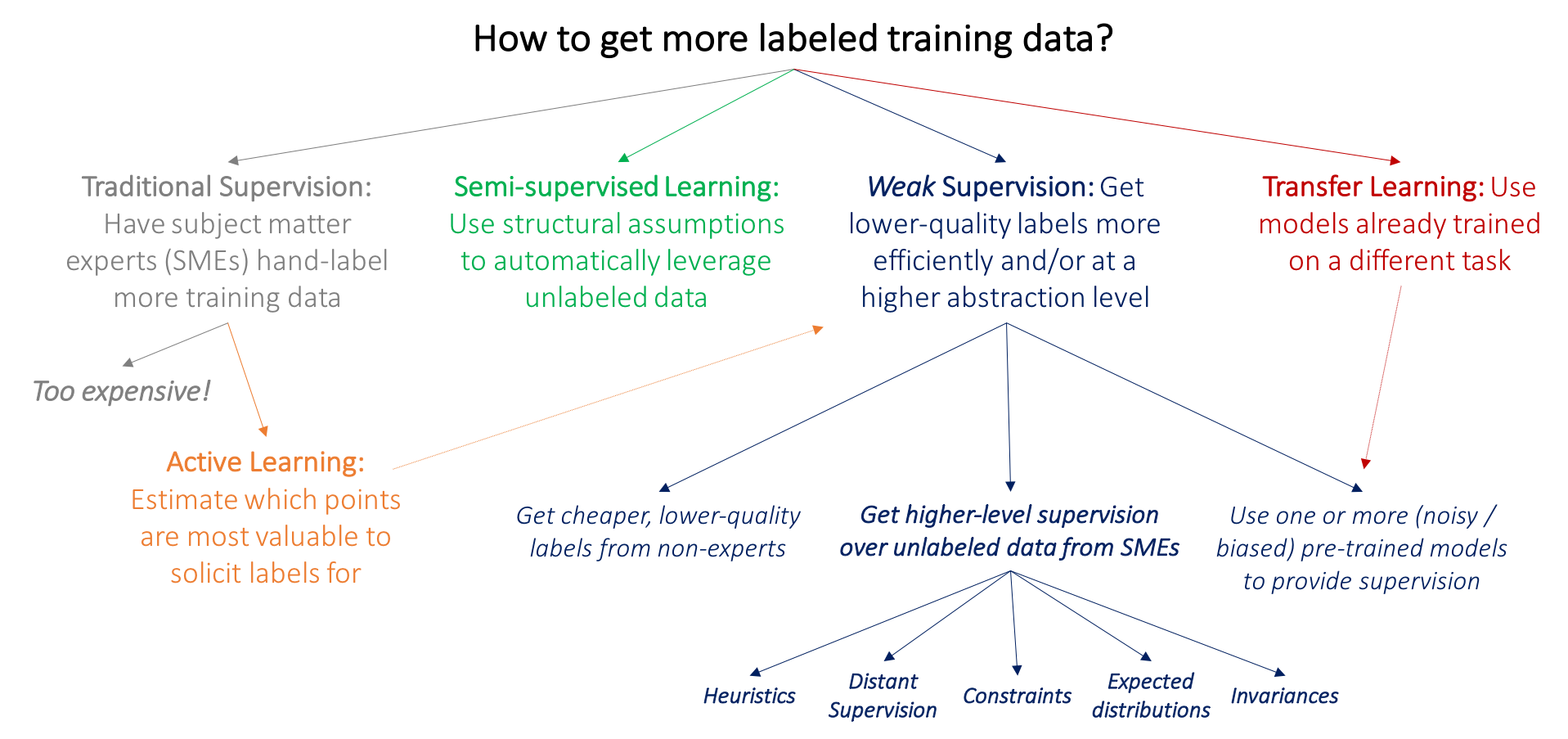
- In active learning, the goal is to make use of subject matter experts more efficiently by having them label data points which are estimated to be most valuable to the model. For example, we might select mammograms that lie close to the current model decision boundary, and ask radiologists to label only these.
- In the semi-supervised learning setting, we have a small labeled training set and a much larger unlabeled data set. At a high level, we then use assumptions about the structure of the data like
smoothness,low dimensional structure, ordistance metricsto leverage the unlabeled data (either as part of a generative model, as a regularizer for a discriminative model, or to learn a compact data representation). Broadly, rather than soliciting more input from subject matter experts, the idea in semi-supervised learning is to leverage domain- and task-agnostic assumptions to exploit the unlabeled data that is often cheaply available in large quantities. - In the standard transfer learning setting, our goal is to take one or more models already trained on a different dataset and apply them to our dataset and task. For example, we might have a large training set for tumors in another part of the body, and classifiers trained on this set, and wish to apply these somehow to our mammography task.
The above paradigms potentially allow us to avoid asking our SME collaborators for additional training labels.
But what if–either in addition, or instead–we could ask SME for various types of higher-level, or otherwise less precise, forms of supervision, which would be faster and easier to provide? For example, what if our radiologists could spend an afternoon specifying a set of heuristics or other resources, that–if handled properly–could effectively replace thousands of training labels? This is the key practical motivation for weak supervision approaches,
![]() Heuristic Examples
Heuristic Examples
# Return a label of SPAM if "http" link in email text, otherwise ABSTAIN
# Return a label of SPAM if substring like "my channel", "my video" are there in the email text.
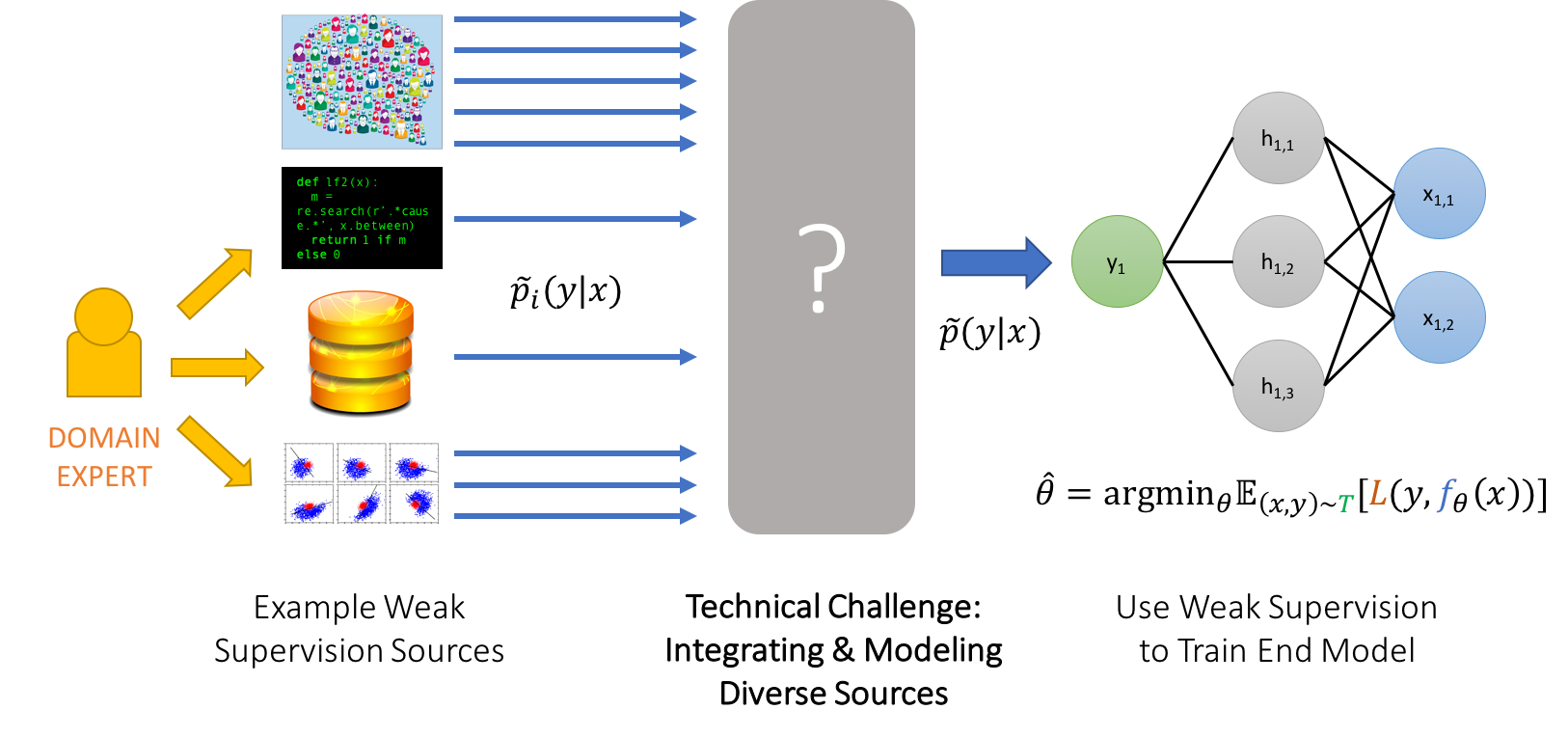
Data Programming:
Data programming: A paradigm for the programmatic creation and modeling of training datasets. Data programming provides a simple, unifying framework for weak supervision, in which training labels are noisy and may be from multiple, potentially overlapping sources.
In data programming, users encode this weak supervision in the form of labeling functions, which are user-defined programs that each provide a label for some subset of the data, and collectively generate a large but potentially overlapping set of training examples.
Many different weak supervision approaches can be expressed as labeling functions.
However labeling functions may have widely varying error rates and may conflict on certain data points. To address this, we model the labeling functions as a generative process, which lets us automatically de-noise the resulting training set by learning the accuracies of the labeling functions along with their correlation structure.
Think data programming as a paradigm by modeling multiple label sources without access to ground truth, and generating probabilistic training labels representing the lineage of the individual labels.
Snorkel architecture
From the original Snorkle paper, the Snorkel architecture is as follows:
Writing Labeling Functions: Rather than hand labeling training data, users of Snorkel write labeling functions, which allow them to express various weak supervision sources such as patterns, heuristics, external knowledge bases, and more.
Modeling Accuracies and Correlations: Snorkel automatically learns a generative model over the labeling functions, which allows it to estimate their accuracies and correlations. This step uses no ground-truth data, learning instead from the agreements and disagreements of the labeling functions.
Training a Discriminative Model: The output of Snorkel is a set of probabilistic labels that can be used to train a wide variety of state-of-the-art machine learning models, such as popular deep learning models. While the generative model is essentially a re-weighted combination of the user-provided labeling functions, which tend to be precise but low-coverage.
Reference:
- Paper: Snorkel: Rapid Training Data Creation with Weak Supervision
- Snorkel Resources
- Weak Supervision: The New Programming Paradigm for Machine Learning
- Book: Semi Supervised Learning
Data Programming: Creating Large Training Sets, Quickly
We will highlight the main points from this NIPS 2016 paper.
Large labeled training sets are the critical building blocks of supervised learning methods and are key enablers of deep learning techniques. For some applications, creating labeled training sets is the most time-consuming and expensive part of applying machine learning. The author therefore proposes a paradigm for the programmatic creation of training sets called data programming in which users express weak supervision strategies or domain heuristics as labeling functions, which are programs that label subsets of the data, but that are noisy and may conflict.
The author shows that by explicitly representing this training set labeling process as a generative model , they can denoise the generated training set, and establish theoretically that we can recover the parameters of these generative models in a handful of settings.
Finally they show how to modify a discriminative loss function to make it noise-aware, and demonstrate their method over a range of discriminative models including logistic regression and LSTMs.
In data programming, users encode this weak supervision in the form of labeling functions, which are user-defined programs that each provide a label for some subset of the data, and collectively generate a large but potentially overlapping set of training labels.
The Data Programming Paradigm
In the remainder of this paper, the author focuses on a binary classification task in which they have a distribution $\pi$ over object and class pairs $(x, y) \in X \times {−1, 1}$, and authors are concerned with minimizing the logistic loss under a linear model given some features $f(x)$.
where without loss of generality, it’s assumed that $\vert \vert f(x) \vert \vert \leq 1$. Then, a labeling function $\lambda_i : X \rightarrowtail (−1, 0, 1)$ is a user-defined function that encodes some domain heuristic, which provides a (non-zero) label for some subset of the objects. As part of a data programming specification, a user provides some $m$ labeling functions, which is denoted in vectorized form as $\lambda : X \rightarrowtail (−1, 0, 1)^m$.
A labeling function need not have perfect accuracy or recall; rather, it represents a pattern that the user wishes to impart to their model and that is easier to encode as a labeling function than as a set of hand-labeled examples.
Importantly, labeling functions can overlap, conflict, and even have dependencies which users can provide as part of the data programming specification; this approach provides a simple framework for these inputs.
Independent Labeling Functions - Generative Model
The author first describes a model in which the labeling functions label independently, given the true label class. Under this model,
- Each labeling function $\lambda_i$ has some probability $\beta_i$ of labeling the $i^{th}$ object (unlabelled data)
- And then has probability $\alpha_i$ of labeling the object correctly; for simplicity it’s assumed here that each class has probability $0.5$. This model has distribution
where $\Lambda \in {−1, 0, 1}^m$ contains the labels output by the labeling functions, and $Y \in {−1, 1}$ is the predicted class. If we allow the parameters $\alpha \in \mathbb{R}^m$ and $\beta \in \mathbb{R}^m$ to vary, specifies a family of generative models.
The first goal will be to learn which parameters $(\alpha, \beta)$ are most consistent with the observations $\rightarrow$ the unlabeled training set $\rightarrow$ using maximum likelihood estimation. To do this for a particular training set $S \subset X$,
In other words, we are maximizing the probability that the observed labels produced on our training examples occur under the generative model in ($1$). In our experiments, we use stochastic gradient descent to solve this problem; since this is a standard technique, we defer its analysis to the appendix.
Learning $(\hat\alpha, \hat\beta)$ means we can generate the labelling distribution $\rightarrow$ i.e. we can generate the labels.
We then use the predictions, $\widetilde{Y} = P_{(\hat\alpha, \hat\beta)}(Y \vert \Lambda)$, as probabilistic training labels.
Noise-Aware Empirical Loss - Discriminative Model
Given that our parameter learning phase (using generative model) has successfully found some $(\hat\alpha, \hat\beta)$ that accurately describe the training set, we can now proceed to estimate the parameter $\hat{w}$ which minimizes the expected risk of a linear model over our feature mapping $f(.)$, given $(\hat\alpha, \hat\beta)$.
To do so, we define the noise-aware empirical risk $\mathcal{L}_{\hat\alpha, \hat\beta}$ with regularization parameter $\rho$, and compute the noise-aware empirical risk minimizer.
This is a logistic regression problem, so it can be solved using stochastic gradient descent as well.
- Why noise-aware? Because it’s based on the learnt $(\hat\alpha, \hat\beta)$ which already captured the noise aware part by learning the generative model over the noisy labels.
This is the overall idea. Now the feature generation $f(x)$ can also be done using automatic feature generation process like LSTM.
For more details, please go through the fantastic paper.
Reference