Survey - BERT
DISCLAIMER: I am not the original author of these contents. I compile from various sources to understand a concept and for future reference as I believe in DRY (Don’t Repeat Yourself !!). This blog is nothing but a SCRIBE for me. Solely for education purposes. I try my best to put all the due credits in the reference. If you find any content is incorrect or credit is missing, please contact me. I will be happy to add/edit them.
Content
- Content
- Introduction
- Self-Attention at a High Level
- BERT - Deeper understanding
- BERT Shortcomings
- BERT Architecture
 Finetune BERT model for domain specific task
Finetune BERT model for domain specific task- BERT Word-Piece embedding
- BERT Tokenizer
- Required Formatting
- Sentence Length & Attention Mask
- BertForSequenceClassification
- Optimizer & Learning Rate Scheduler
- BERT Inner Workings
- Implementation - Attention, Transformer, GPT2, BERT
- Sentence Transformers: Sentence Embeddings using BERT a.k.a Sentence BERT
*In case the above link is broken, click here
Introduction
History
2018 was a breakthrough year in NLP. Transfer learning, particularly models like Allen AI’s ELMO, OpenAI’s Open-GPT, and Google’s BERT allowed researchers to smash multiple benchmarks with minimal task-specific fine-tuning and provided the rest of the NLP community with pretrained models that could easily (with less data and less compute time) be fine-tuned and implemented to produce state of the art results. Unfortunately, for many starting out in NLP and even for some experienced practicioners, the theory and practical application of these powerful models is still not well understood.
What is BERT?
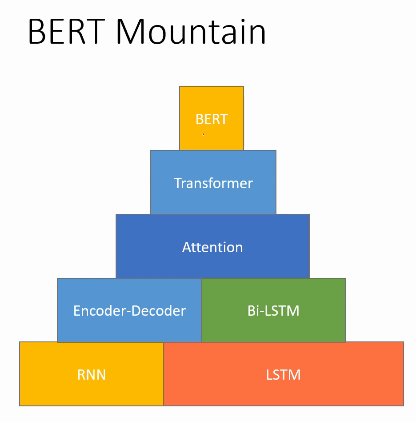
TL;DR: To Understand BERT, understand Attention and Transformer thoroughly.
MUST READ:
Read this first.
BERT (Bidirectional Encoder Representations from Transformers), released in late 2018, is the model we will use in this tutorial to provide readers with a better understanding of and practical guidance for using transfer learning models in NLP. BERT is a method of pretraining language representations that was used to create models that NLP practicioners can then download and use for free. You can either use these models to extract high quality language features from your text data, or you can fine-tune these models on a specific task (classification, entity recognition, question answering, etc.) with your own data to produce state of the art predictions.
This post will explain how you can modify and fine-tune BERT to create a powerful NLP model that quickly gives you state of the art results.
A Shift in NLP
This shift to transfer learning parallels the same shift that took place in computer vision a few years ago. Creating a good deep learning network for computer vision tasks can take millions of parameters and be very expensive to train. Researchers discovered that deep networks learn hierarchical feature representations (simple features like edges at the lowest layers with gradually more complex features at higher layers). Rather than training a new network from scratch each time, the lower layers of a trained network with generalized image features could be copied and transfered for use in another network with a different task. It soon became common practice to download a pre-trained deep network and quickly retrain it for the new task or add additional layers on top - vastly preferable to the expensive process of training a network from scratch. For many, the introduction of deep pre-trained language models in 2018 (ELMO, BERT, ULMFIT, Open-GPT, etc.) signals the same shift to transfer learning in NLP that computer vision saw.
Reference:
- Amazing blog by Chris McCormick
- Amazing Youtube Lectures by Chris McCormick
- Important Colab Notebook by Chris McCormick
- Handson by Abhishek Thakur
![]()
Before digging into BERT, it’s advised to read the Transformer blog by Jay Alammar.
Self-Attention at a High Level
Say the following sentence is an input sentence we want to translate:
The animal didn't cross the street because it was too tired
What does it in this sentence refer to? Is it referring to the street or to the animal? It’s a simple question to a human, but not as simple to an algorithm.
When the model is processing the word it, self-attention allows it to associate it with animal.
As the model processes each word (each position in the input sequence), self attention allows it to look at other positions in the input sequence for clues that can help lead to a better encoding for this word.
- If you’re familiar with RNNs, think of how maintaining a hidden state allows an RNN to incorporate its representation of previous words/vectors it has processed with the current one it’s processing.
- Self-attention is the method the Transformer uses to bring the
understandingof other relevant words into the one we’re currently processing.

MUST read self attention details from Jay Alammar’s blog.
For more deeper understanding of attention please look into this summary blog.
![]() Reference:
Reference:
![]()
BERT - Deeper understanding
One of the biggest challenges in natural language processing (NLP) is the
shortage of task specific training data.
Because NLP is a diversified field with many distinct tasks, most task-specific datasets contain only a few thousand or a few hundred thousand human-labeled training examples.
However, modern deep learning-based NLP models see benefits from much larger amounts of data, improving when trained on millions, or billions, of annotated training examples. To help close this gap in data, researchers have developed a variety of techniques for training general purpose language representation models using the enormous amount of unannotated text on the web (known as pre-training).
The pre-trained model can then be fine-tuned on small annotated data for NLP tasks like question answering and sentiment analysis, resulting in substantial accuracy improvements compared to training on these datasets from scratch.
TL;DR: This idea of training on large unlabelled data and later fine tuning on task specific small labeled data is called a form of Semi Supervised (click here) learning.
What Makes BERT Different?
BERT builds upon recent work in pre-training contextual representations — including Semi-supervised Sequence Learning, Generative Pre-Training, ELMo, and ULMFit. However, unlike these previous models, BERT is the
- First deeply bidirectional
- Unsupervised language representation, pre-trained using only a plain text corpus (in this case, Wikipedia).
Why does this matter? {: .red}
Pre-trained representations can either be
- Context-free [word2vec, Glove]
- Unidirectional
- Bi Derectoinal
- Contextual
- Unidirectional: OpenAI GPT
- Biderectional
- Deep: BERT
- Shallow: ELMo
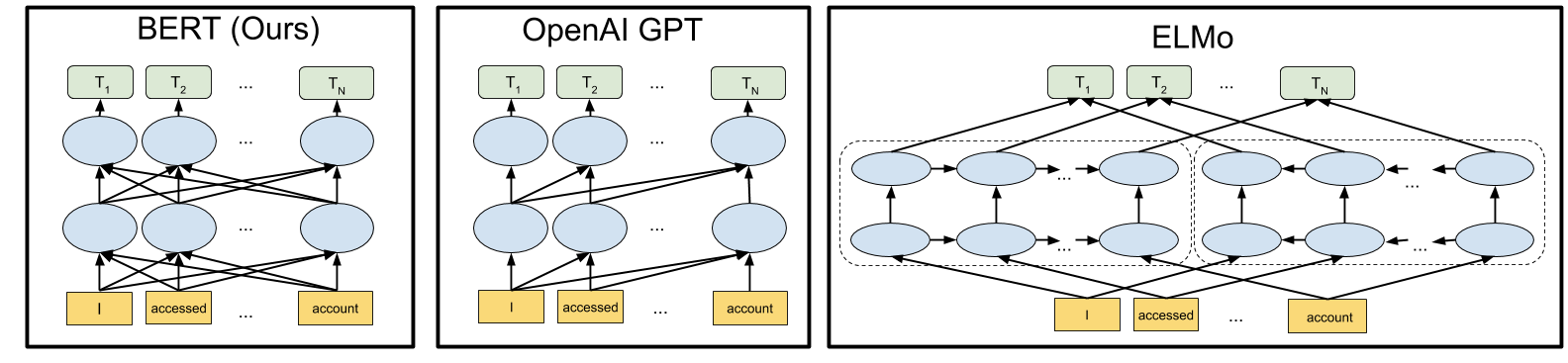
Contextual representations can further be unidirectional or bidirectional. Context-free models such as word2vec or GloVe generate a single word embedding representation for each word in the vocabulary. For example, the word bank would have the same context-free representation in bank account and bank of the river.
Contextual models instead generate a representation of each word that is based on the other words in the sentence. For example, in the sentence I accessed the bank account, a unidirectional contextual model would represent bank based on I accessed the but not account. However, BERT represents bank using both its previous and next context: I accessed the _____ account $\rightarrow$ starting from the very bottom of a deep neural network, making it deeply bidirectional.
The Strength of Bidirectionality {: .red}
If bidirectionality is so powerful, why hasn’t it been done before? To understand why, consider that unidirectional models are efficiently trained by predicting each word conditioned on the previous words in the sentence. However, it is not possible to train bidirectional models by simply conditioning each word on its previous and next words, since this would allow the word that’s being predicted to indirectly see itself in a multi-layer model. Which is not correct. So we need to design a task on which the model can be trained with correct bi-directionality.
![]() Masked Language Model: To solve this problem, the straightforward technique is to mask out some of the words in the input and then condition each word bidirectionally to predict the masked words. For example:
Masked Language Model: To solve this problem, the straightforward technique is to mask out some of the words in the input and then condition each word bidirectionally to predict the masked words. For example:

Masking means that the model looks in both directions and it uses the full context of the sentence, both left and right surroundings, in order to predict the masked word. Unlike the previous language models, it takes both the previous and next tokens into account at the same time. The existing combined left-to-right and right-to-left LSTM based models were missing this same-time part. (It might be more accurate to say that BERT is non-directional though.)
![]() Next Sentence Prediction: BERT also learns to model relationships between sentences by pre-training on a very simple task that can be generated from any text corpus: Given two sentences A and B, is B the actual next sentence that comes after A in the corpus, or just a random sentence? For example:
Next Sentence Prediction: BERT also learns to model relationships between sentences by pre-training on a very simple task that can be generated from any text corpus: Given two sentences A and B, is B the actual next sentence that comes after A in the corpus, or just a random sentence? For example:
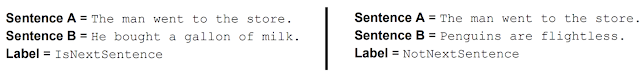
*Now read this as a continuation. ![]()
Reference:
![]()
BERT Shortcomings
- BERT is very large. $\sim 109$M parameters with total size $\sim 417$MB.
- Slow fine-tuning.
- Slow inference.
- Jargon (Domain specific language)
-
NOT all NLP applications can be solved using BERT
-
 Classification, NER, POS Tagging, QnA
Classification, NER, POS Tagging, QnA -
 Language Modelling, Text Generation, Translation
Language Modelling, Text Generation, Translation
-
Reference:
![]()
BERT Architecture
BERT relies on a Transformer (the attention mechanism that learns contextual relationships between words in a text). A basic Transformer consists of an encoder to read the text input and a decoder to produce a prediction for the task. Since BERT’s goal is to generate a language representation model, it only needs the encoder part.
The input to the encoder for BERT is a sequence of tokens, which are first converted into vectors and then processed in the neural network. But before processing can start, BERT needs the input to be massaged and decorated with some extra metadata:
- Token embeddings: A [CLS] token is added to the input word tokens at the beginning of the first sentence and a [SEP] token is inserted at the end of each sentence.
-
Segment embeddings: A marker indicating
Sentence AorSentence Bis added to each token. This allows the encoder to distinguish between sentences. Helpful in nex-sentence prediction task.

The input representation for BERT: The input embeddings are the sum of the token embeddings, the segmentation embeddings and the position embeddings.
Train the model
![]() Masked LM (MLM)
Masked LM (MLM)
The idea here is “simple”: Randomly mask out $15\%$ of the words in the input — replacing them with a [MASK] token — run the entire sequence through the BERT attention based encoder and then predict only the masked words, based on the context provided by the other non-masked words in the sequence.
Problem: However, there is a problem with this naive masking approach — the model only tries to predict when the [MASK] token is present in the input, while we want the model to try to predict the correct tokens regardless of what token is present in the input. To deal with this issue, out of the $15\%$ of the tokens selected for masking:
- $80\%$ of the tokens are actually replaced with the token [MASK].
- $10\%$ of the time tokens are replaced with a random token.
- $10\%$ of the time tokens are left unchanged.
While training the BERT loss function considers only the prediction of the masked tokens and ignores the prediction of the non-masked ones. This results in a model that converges much more slowly than left-to-right or right-to-left models.
![]() Next Sentence Prediction (NSP)
Next Sentence Prediction (NSP)
In order to understand relationship between two sentences, BERT training process also uses next sentence prediction. A pre-trained model with this kind of understanding is relevant for tasks like question answering. During training the model gets as input: pairs of sentences and it learns to predict if the second sentence is the next sentence in the original text as well.
As we have seen earlier, BERT separates sentences with a special [SEP] token. During training the model is fed with two input sentences at a time such that:
- $50\%$ of the time the second sentence comes after the first one.
- $50\%$ of the time it is a a random sentence from the full corpus.
BERT is then required to predict whether the second sentence is random or not, with the assumption that the random sentence will be disconnected from the first sentence:

To predict if the second sentence is connected to the first one or not, basically the complete input sequence goes through the Transformer based model, the output of the [CLS] token is transformed into a 2×1 shaped vector using a simple classification layer, and the IsNext-Label is assigned using softmax.
The model is trained jointly with both Masked LM and Next Sentence Prediction together. This is to minimize the combined loss function of the two strategies — together is better.
Loss function
Reference:
![]()
Finetune BERT model for domain specific task
Reference:
-
Blog and Code

- Good for understanding transfer learning
-
Code - BERT Model Finetuning using Masked Language Modeling objective

-
Transfer Learning for NLP: Fine-Tuning BERT for Text Classification
- Try this first. Easier to understand the objective
- Finetune BERT for text classification - Abhishek Thakur
- BERT repo from google
-
Spam classifcation by msank00

![]()
BERT Word-Piece embedding
- BERT is
pretrained$\rightarrow$ Vocabulary is FIXED. - Breaks down
unknown wordsinto sub-words.

- A sub-word exists for every character.
import torch
from pytorch_pretrained_bert import BertTokenizer
# Load pre-trained model tokenizer (vocabulary)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
with open("vocabulary.txt", 'w') as f:
# For each token...
for token in tokenizer.vocab.keys():
# Write it out and escape any unicode characters.
f.write(token + '\n')
From perusing the vocab, I’m seeing that:
# The first 999 tokens (1-indexed) appear to be reserved, and most are of the form [unused957].
1 - [PAD]
101 - [UNK]
102 - [CLS]
103 - [SEP]
104 - [MASK]
# Rows 1000-1996 appear to be a dump of individual characters.
They do not appear to be sorted by frequency (e.g., the letters of the alphabet are all in sequence).
# The first word is "the" at position 1997.
From there, the words appear to be sorted by frequency.
# The top ~18 words are whole words, and then number 2016 is ##s, presumably the most common sub-word.
# The last whole word is at 29612, "necessitated"
Number of single character tokens: 997
! $ % & ( ) * + , - . / 0 1 2 3 4 5 6 7 8 9 : ; < = > ? @ [ \ ] ^ _ ` a b
c d e f g h i j k l m n o p q r s t u v w x y z { | } ~ ¡ ¢ £ ¤ ¥ ¦ § ¨ © ª « ¬
® ° ± ² ³ ´ µ ¶ · ¹ º » ¼ ½ ¾ ¿ × ß æ ð ÷ ø þ đ ħ ı ł ŋ œ ƒ ɐ ɑ ɒ ɔ ɕ ə ɛ ɡ ɣ ɨ
ɪ ɫ ɬ ɯ ɲ ɴ ɹ ɾ ʀ ʁ ʂ ʃ ʉ ʊ ʋ ʌ ʎ ʐ ʑ ʒ ʔ ʰ ʲ ʳ ʷ ʸ ʻ ʼ ʾ ʿ ˈ ː ˡ ˢ ˣ ˤ α β γ δ
ε ζ η θ ι κ λ μ ν ξ ο π ρ ς σ τ υ φ χ ψ ω а б в г д е ж з и к л м н о п р с т у
ф х ц ч ш щ ъ ы ь э ю я ђ є і ј љ њ ћ ӏ ա բ գ դ ե թ ի լ կ հ մ յ ն ո պ ս վ տ ր ւ
ք ־ א ב ג ד ה ו ז ח ט י ך כ ל ם מ ן נ ס ע ף פ ץ צ ק ר ש ת ، ء ا ب ة ت ث ج ح خ د
ذ ر ز س ش ص ض ط ظ ع غ ـ ف ق ك ل م ن ه و ى ي ٹ پ چ ک گ ں ھ ہ ی ے अ आ उ ए क ख ग च
ज ट ड ण त थ द ध न प ब भ म य र ल व श ष स ह ा ि ी ो । ॥ ং অ আ ই উ এ ও ক খ গ চ ছ জ
ট ড ণ ত থ দ ধ ন প ব ভ ম য র ল শ ষ স হ া ি ী ে க ச ட த ந ன ப ம ய ர ல ள வ ா ி ு ே
ை ನ ರ ಾ ක ය ර ල ව ා ก ง ต ท น พ ม ย ร ล ว ส อ า เ ་ ། ག ང ད ན པ བ མ འ ར ལ ས မ ა
ბ გ დ ე ვ თ ი კ ლ მ ნ ო რ ს ტ უ ᄀ ᄂ ᄃ ᄅ ᄆ ᄇ ᄉ ᄊ ᄋ ᄌ ᄎ ᄏ ᄐ ᄑ ᄒ ᅡ ᅢ ᅥ ᅦ ᅧ ᅩ ᅪ ᅭ ᅮ
ᅯ ᅲ ᅳ ᅴ ᅵ ᆨ ᆫ ᆯ ᆷ ᆸ ᆼ ᴬ ᴮ ᴰ ᴵ ᴺ ᵀ ᵃ ᵇ ᵈ ᵉ ᵍ ᵏ ᵐ ᵒ ᵖ ᵗ ᵘ ᵢ ᵣ ᵤ ᵥ ᶜ ᶠ ‐ ‑ ‒ – — ―
‖ ‘ ’ ‚ “ ” „ † ‡ • … ‰ ′ ″ › ‿ ⁄ ⁰ ⁱ ⁴ ⁵ ⁶ ⁷ ⁸ ⁹ ⁺ ⁻ ⁿ ₀ ₁ ₂ ₃ ₄ ₅ ₆ ₇ ₈ ₉ ₊ ₍
₎ ₐ ₑ ₒ ₓ ₕ ₖ ₗ ₘ ₙ ₚ ₛ ₜ ₤ ₩ € ₱ ₹ ℓ № ℝ ™ ⅓ ⅔ ← ↑ → ↓ ↔ ↦ ⇄ ⇌ ⇒ ∂ ∅ ∆ ∇ ∈ − ∗
∘ √ ∞ ∧ ∨ ∩ ∪ ≈ ≡ ≤ ≥ ⊂ ⊆ ⊕ ⊗ ⋅ ─ │ ■ ▪ ● ★ ☆ ☉ ♠ ♣ ♥ ♦ ♭ ♯ ⟨ ⟩ ⱼ ⺩ ⺼ ⽥ 、 。 〈 〉
《 》 「 」 『 』 〜 あ い う え お か き く け こ さ し す せ そ た ち っ つ て と な に ぬ ね の は ひ ふ へ ほ ま み
む め も や ゆ よ ら り る れ ろ を ん ァ ア ィ イ ウ ェ エ オ カ キ ク ケ コ サ シ ス セ タ チ ッ ツ テ ト ナ ニ ノ ハ
ヒ フ ヘ ホ マ ミ ム メ モ ャ ュ ョ ラ リ ル レ ロ ワ ン ・ ー 一 三 上 下 不 世 中 主 久 之 也 事 二 五 井 京 人 亻 仁
介 代 仮 伊 会 佐 侍 保 信 健 元 光 八 公 内 出 分 前 劉 力 加 勝 北 区 十 千 南 博 原 口 古 史 司 合 吉 同 名 和 囗 四
国 國 土 地 坂 城 堂 場 士 夏 外 大 天 太 夫 奈 女 子 学 宀 宇 安 宗 定 宣 宮 家 宿 寺 將 小 尚 山 岡 島 崎 川 州 巿 帝
平 年 幸 广 弘 張 彳 後 御 德 心 忄 志 忠 愛 成 我 戦 戸 手 扌 政 文 新 方 日 明 星 春 昭 智 曲 書 月 有 朝 木 本 李 村
東 松 林 森 楊 樹 橋 歌 止 正 武 比 氏 民 水 氵 氷 永 江 沢 河 治 法 海 清 漢 瀬 火 版 犬 王 生 田 男 疒 発 白 的 皇 目
相 省 真 石 示 社 神 福 禾 秀 秋 空 立 章 竹 糹 美 義 耳 良 艹 花 英 華 葉 藤 行 街 西 見 訁 語 谷 貝 貴 車 軍 辶 道 郎
郡 部 都 里 野 金 鈴 镇 長 門 間 阝 阿 陳 陽 雄 青 面 風 食 香 馬 高 龍 龸 fi fl ! ( ) , - . / : ? ~
" ' #
Reference:
![]()
BERT Tokenizer
To feed our text to BERT, it must be split into tokens, and then these tokens must be mapped to their index in the tokenizer vocabulary.
The tokenization must be performed by the tokenizer included with BERT – the below cell will download this for us. We’ll be using the BERT base model with uncased version.
Note:
- BERT has
baseandlargemodel. Butlargemodel size is quite big, so we work withbasemodel. -
uncasemeans no Upper case letters in the vocabulary
from transformers import BertTokenizer
# Load the BERT tokenizer.
print('Loading BERT tokenizer...')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', do_lower_case=True)
# Loading BERT tokenizer...
Let’s apply the tokenizer to one sentence just to see the output.
# Print the original sentence.
print(' Original: ', sentences[0])
# Print the sentence split into tokens.
print('Tokenized: ', tokenizer.tokenize(sentences[0]))
# Print the sentence mapped to token ids.
print('Token IDs: ', tokenizer.convert_tokens_to_ids(tokenizer.tokenize(sentences[0])))
# Output:
# Original: Our friends won't buy this analysis, let alone the next one we propose.
# Tokenized: ['our', 'friends', 'won', "'", 't', 'buy', 'this', 'analysis', ',', 'let', 'alone', 'the', 'next', 'one', 'we', 'propose', '.']
# Token IDs: [2256, 2814, 2180, 1005, 1056, 4965, 2023, 4106, 1010, 2292, 2894, 1996, 2279, 2028, 2057, 16599, 1012]
Reference:
![]()
Required Formatting
We are required to:
- Add special tokens to the start and end of each sentence.
- Pad & truncate all sentences to a single constant length.
- Explicitly differentiate real tokens from padding tokens with the
attention mask.
Special Tokens
[SEP]
At the end of every sentence, we need to append the special [SEP] token.
This token is an artifact of two-sentence tasks, where BERT is given two separate sentences and asked to determine something (e.g., can the answer to the question in sentence A be found in sentence B?).
I am not certain yet why the token is still required when we have only single-sentence input, but it is!
[CLS]
For classification tasks, we must pre-pend the special [CLS] token to the beginning of every sentence.
This token has special significance. BERT consists of 12 Transformer layers stacked on top of each other. Each transformer takes in a list of token embeddings, and produces the same number of embeddings on the output (but with the feature values changed, of course!).
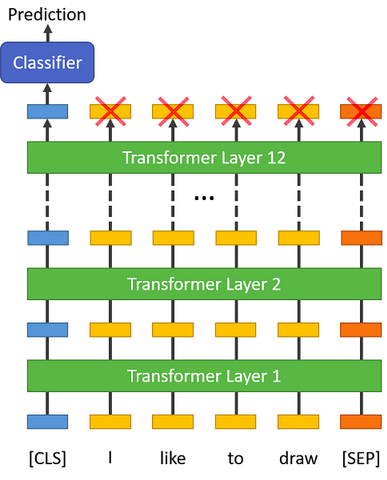
On the output of the final (12th) transformer, only the first embedding (corresponding to the [CLS] token) is used by the classifier.
“The first token of every sequence is always a special classification token ([CLS]). The final hidden state corresponding to this token is used as the aggregate sequence representation for classification tasks.” (from the BERT paper)
You might think to try some pooling strategy over the final embeddings, but this isn’t necessary. Because BERT is trained to only use this [CLS] token for classification, we know that the model has been motivated to encode everything it needs for the classification step into that single 768-value embedding vector. It’s already done the pooling for us!
Reference:
![]()
Sentence Length & Attention Mask
The sentences in our dataset obviously have varying lengths, so how does BERT handle this?
BERT has two constraints:
- All sentences must be padded or truncated to a single, fixed length.
- The maximum sentence length is $512$ tokens.
Padding is done with a special [PAD] token, which is at index $0$ in the BERT vocabulary. The below illustration demonstrates padding out to a MAX_LEN of $8$ tokens.
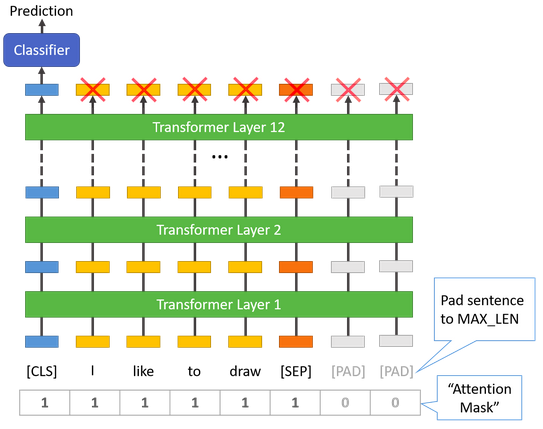
The “Attention Mask” is simply an array of 1s and 0s indicating which tokens are padding and which aren’t (seems kind of redundant, doesn’t it?!). This mask tells the “Self-Attention” mechanism in BERT not to incorporate these PAD tokens into its interpretation of the sentence.
The maximum length does impact training and evaluation speed, however. For example, with a Tesla K80:
- MAX_LEN = $128\rightarrow$ Training epochs take $\sim 5:28$ each
- MAX_LEN = $64\rightarrow$ Training epochs take $\sim 2:57$ each
Reference:
![]()
BertForSequenceClassification
For this task, we first want to modify the pre-trained BERT model to give outputs for classification, and then we want to continue training the model on our dataset until that the entire model, end-to-end, is well-suited for our task.
Thankfully, the huggingface pytorch implementation includes a set of interfaces designed for a variety of NLP tasks. Though these interfaces are all built on top of a trained BERT model, each has different top layers and output types designed to accomodate their specific NLP task.
Here is the current list of classes provided for fine-tuning:
- BertModel
- BertForPreTraining
- BertForMaskedLM
- BertForNextSentencePrediction
- BertForSequenceClassification - The one we’ll use.
- BertForTokenClassification
- BertForQuestionAnswering
The documentation for these can be found under here.
- We’ll be using BertForSequenceClassification. This is the normal BERT model with an added
single linear layeron top for classification that we will use as a sentence classifier. - As we feed input data, the entire pre-trained BERT model and the additional untrained classification layer is trained on our specific task.
OK, let’s load BERT! There are a few different pre-trained BERT models available. bert-base-uncased means the version that has only lowercase letters (uncased) and is the smaller version of the two (base vs large).
The documentation for from_pretrained can be found here, with the additional parameters defined here.
from transformers import BertForSequenceClassification, AdamW, BertConfig
# Load BertForSequenceClassification, the pretrained BERT model with a single
# linear classification layer on top.
model = BertForSequenceClassification.from_pretrained(
"bert-base-uncased", # Use the 12-layer BERT model, with an uncased vocab.
num_labels = 2, # The number of output labels--2 for binary classification.
# You can increase this for multi-class tasks.
output_attentions = False, # Whether the model returns attentions weights.
output_hidden_states = False, # Whether the model returns all hidden-states.
)
# Tell pytorch to run this model on the GPU.
model.cuda()
Just for curiosity’s sake, we can browse all of the model’s parameters by name here.
In the below cell, I’ve printed out the names and dimensions of the weights for:
- The embedding layer.
- The first of the twelve transformers.
- The output layer.
# Get all of the model's parameters as a list of tuples.
params = list(model.named_parameters())
print('The BERT model has {:} different named parameters.\n'.format(len(params)))
print('==== Embedding Layer ====\n')
for p in params[0:5]:
print("{:<55} {:>12}".format(p[0], str(tuple(p[1].size()))))
print('\n==== First Transformer ====\n')
for p in params[5:21]:
print("{:<55} {:>12}".format(p[0], str(tuple(p[1].size()))))
print('\n==== Output Layer ====\n')
for p in params[-4:]:
print("{:<55} {:>12}".format(p[0], str(tuple(p[1].size()))))
The BERT model has 201 different named parameters.
==== Embedding Layer ====
bert.embeddings.word_embeddings.weight (30522, 768)
bert.embeddings.position_embeddings.weight (512, 768)
bert.embeddings.token_type_embeddings.weight (2, 768)
bert.embeddings.LayerNorm.weight (768,)
bert.embeddings.LayerNorm.bias (768,)
==== First Transformer ====
bert.encoder.layer.0.attention.self.query.weight (768, 768)
bert.encoder.layer.0.attention.self.query.bias (768,)
bert.encoder.layer.0.attention.self.key.weight (768, 768)
bert.encoder.layer.0.attention.self.key.bias (768,)
bert.encoder.layer.0.attention.self.value.weight (768, 768)
bert.encoder.layer.0.attention.self.value.bias (768,)
bert.encoder.layer.0.attention.output.dense.weight (768, 768)
bert.encoder.layer.0.attention.output.dense.bias (768,)
bert.encoder.layer.0.attention.output.LayerNorm.weight (768,)
bert.encoder.layer.0.attention.output.LayerNorm.bias (768,)
bert.encoder.layer.0.intermediate.dense.weight (3072, 768)
bert.encoder.layer.0.intermediate.dense.bias (3072,)
bert.encoder.layer.0.output.dense.weight (768, 3072)
bert.encoder.layer.0.output.dense.bias (768,)
bert.encoder.layer.0.output.LayerNorm.weight (768,)
bert.encoder.layer.0.output.LayerNorm.bias (768,)
==== Output Layer ====
bert.pooler.dense.weight (768, 768)
bert.pooler.dense.bias (768,)
classifier.weight (2, 768)
classifier.bias (2,)
Reference:
![]()
Optimizer & Learning Rate Scheduler
Now that we have our model loaded we need to grab the training hyperparameters from within the stored model.
For the purposes of fine-tuning, the authors recommend choosing from the following values (from Appendix A.3 of the BERT paper):
- Batch size: $16$, $32$
- Learning rate (Adam): $5e^{-5}$, $3e^{-5}$, $2e^{-5}$
- Number of epochs: $2$, $3$, $4$
We chose:
- Batch size: 32 (set when creating our DataLoaders)
- Learning rate: $2e^{-5}$
- Epochs: 4 (we’ll see that this is probably too many…)
The epsilon parameter $eps = 1e^{-8}$ is “a very small number to prevent any division by zero in the implementation” (from here).
You can find the creation of the AdamW optimizer in run_glue.py here.
NOTE: Please check this amazing script from Huggingface ![]() , run_glue.py.
, run_glue.py.
Reference:
![]()
BERT Inner Workings
Original NMT
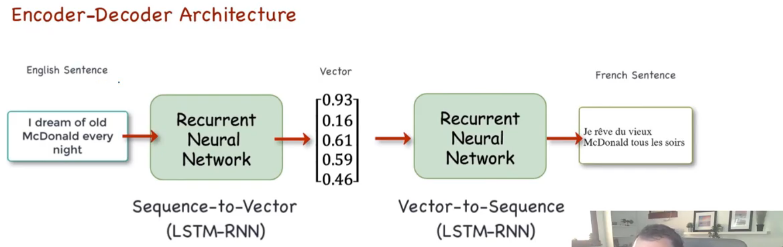
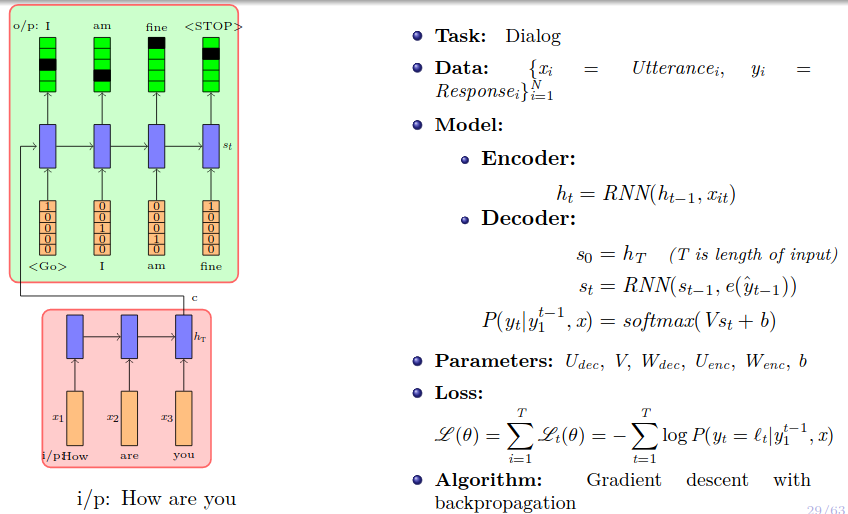
2 RNN, Encoder and Decoder.
- Decoder generates probability distribution for each of the word in the vocab and you pick which has the highest probability.
- Next given the first decoder output what will be the next decoder output and so on.You can add
Teacher-Forcinghere if required.
Google NMT
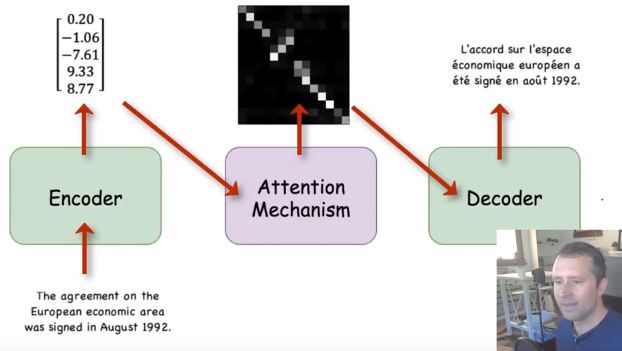

- Google added the
attention(the concept existed already) - First major use of attention in NLP.
- In Original NMT, entire sentence is encoded into one encoding vector.
- But google,
instead of looking at the single encoded output vector, they look at the individual hidden state for all the input words and attention mechanism takes a linear combination of those hidden states (gives different weights to different input words’ hidden representation).

MUST watch lecture 16, prof. Mikesh IIT-M for in-depth attention understanding ![]()
![]()
- So when the decoder tries to output the word
European, hope that the attention mechanism already giving lots of weight to the input wordEuropeanand less weight to the other words. - In general attention tells the model to which words it should focus on.
- The biggest benefit of Transformer model is it’s ability to run in parallel.
BERT Architecture
- BERT is an enhancement of the Transformer model (Attention is all you need).
- Transformer model is an encoder-decoder model with stack of 6 encode and decoder.
- In BERT the decoder part is dropped and numbers of encoder layers are increased from 6 to 12
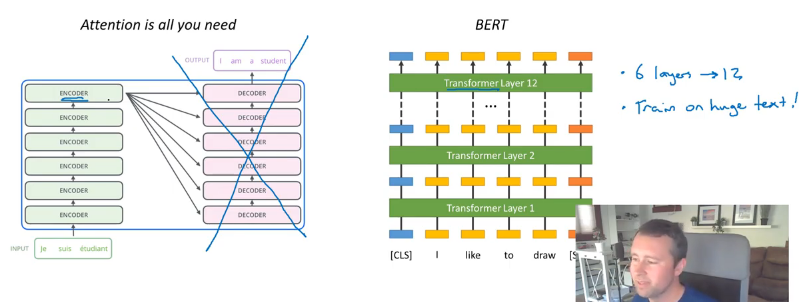
- Now the main challenge for this model is how to train or on which kind of task you will train this model.
- 2 fake tasks are created
- Predict the masked word
- Next sentence prediction (was
Sentence Bfound immediately afterSentence A?)
BERT is conceptually not so simple but empirically very powerful.
The BERT Encoder block implements the base version of the BERT network. It is composed of 12 successive transformer layers, each having 12 attention heads. The total number of parameters is 110 million.

The architecture is reverse. Input at the top and the output at the bottom.
Every token in the input of the block is first embedded into a learned 768-long embedding vector.
Each embedding vector is then transformed progressively every time it traverses one of the BERT Encoder layers:
- Through linear projections, every embedding vector creates a triplet of
64-long vectors, called the key, query, and value vectors - The key, query, and value vectors from all the embeddings pass through a self-attention head, which outputs one
64-long vectorfor each input triplet. - Every output vector from the self-attention head is a function of the whole input sequence, which is what makes BERT context-aware.
- A single embedding vector uses different linear projections to create
12 uniquetriplets of key, query, and value vectors, which all go through their own self-attention head. - This allows each self-attention head to focus on different aspects of how the tokens interact with each other.
- The output from all the self-attention heads are first concatenated together, then they go through another linear projection and a feed-forward layer, which helps to utilize deep non-linearity
- Residual connections from previous states are also used to increase robustness.
The result is a sequence of transformed embedding vectors, which are sent through the same layer structure 11 more times.
After the 12th encoding layer, the embedding vectors have been transformed to contain more accurate information about each token. You can choose if you want the BERT Encoder block to return all of them or only the first one (corresponding to the [CLS] token), which is often sufficient for classification tasks.
Architecture explained
As you might already understood BERT is based on Transformer. The Transformer has $8$ heads of length $64$, i.e, gives embedding size of $512$. Whereas BERT has $12$ heads with same length and then embedding size is $768$
![]() Reference:
Reference:
-
How Google Translate Works - YT Video
-
BERT Inner Workings I by ChrisMcCormickAI
-
BERT Inner Workings III by ChrisMcCormickAI
-
BERT Architecture
![]()
Implementation - Attention, Transformer, GPT2, BERT
![]() Core Reading:
Core Reading:
![]()
Sentence Transformers: Sentence Embeddings using BERT a.k.a Sentence BERT
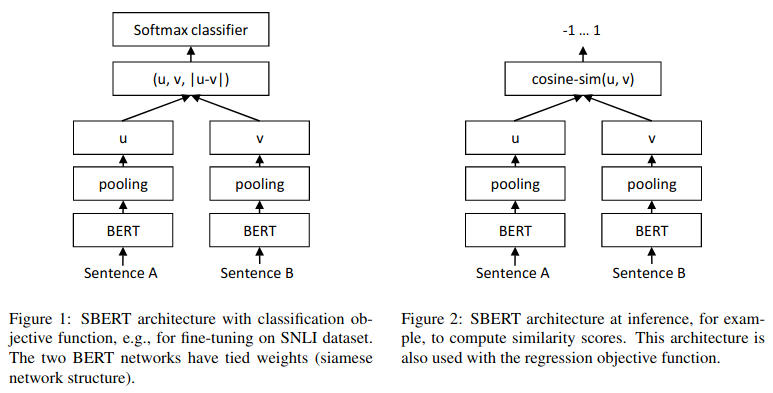
From the abstract of the original paper
BERT (Devlin et al., $2018$) and RoBERTa (Liu et al., 2019) has set a new state-of-the-art performance on sentence-pair regression tasks like semantic textual similarity (STS). However, it requires that both sentences are fed into the network, which causes a massive computational overhead: Finding the most similar pair in a collection of 10,000 sentences requires about 50 million inference computations (~65 hours) with BERT. The construction of BERT makes it unsuitable for semantic similarity search as well as for unsupervised tasks like clustering.
In this paper, we present Sentence-BERT (SBERT), a modification of the pretrained BERT network that use siamese and triplet network structures to derive semantically meaningful sentence embeddings that can be compared using cosine-similarity. This reduces the effort for finding the most similar pair from 65 hours with BERT / RoBERTa to about 5 seconds with SBERT, while maintaining the accuracy from BERT.
How to use it in code
# install the package
pip install -U sentence-transformers
# download a pretrained model.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('bert-base-nli-mean-tokens')
# Then provide some sentences to the model.
sentences = ['This framework generates embeddings for each input sentence',
'Sentences are passed as a list of string.',
'The quick brown fox jumps over the lazy dog.']
sentence_embeddings = model.encode(sentences)
# And that's it already. We now have a list of numpy arrays with the embeddings.
for sentence, embedding in zip(sentences, sentence_embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding)
print("")
**for more details check the pypi repository
![]() Reference:
Reference:
![]()